- Home /
- Resources /
- Learning center /
- What is Infrastruc...
What is Infrastructure-as-Code?
All of your infrastructure created, managed and reproduced from a few easy files
What is Infrastructure-as-Code, or "IaC"? Why does it matter to you, deploying and operating infrastructure, and how can it help you run a better operation, while sleeping soundly at night?
Let's take a walk through deploying your infrastructure for your mission-critical, production-supporting business application.
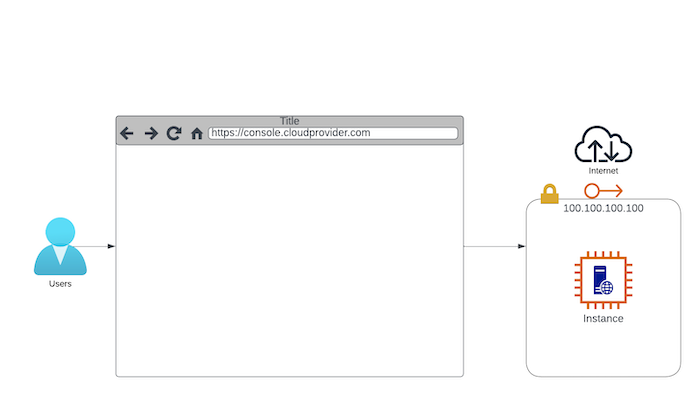
When the business was young, you didn't need more than a server and an IP address. No problem! You opened a Web browser, went to a cloud provider's console, launched them and away things went. Sounds pretty good so far.
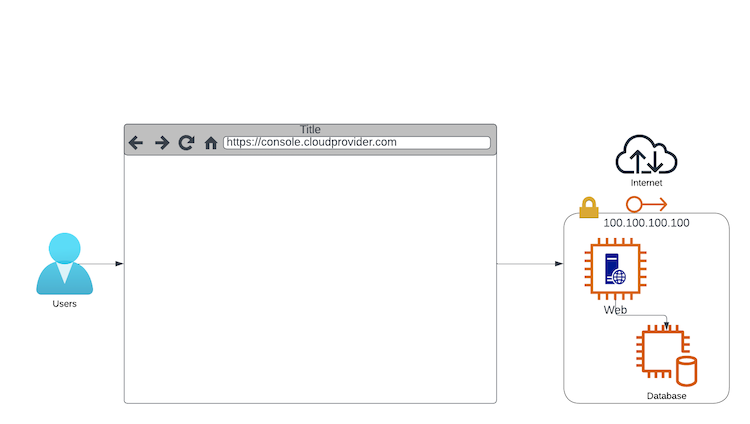
Over time, your service grew, so you decided to separate the database to its own server, and add a few more Web servers. Pretty easy, you can do it from the console again.
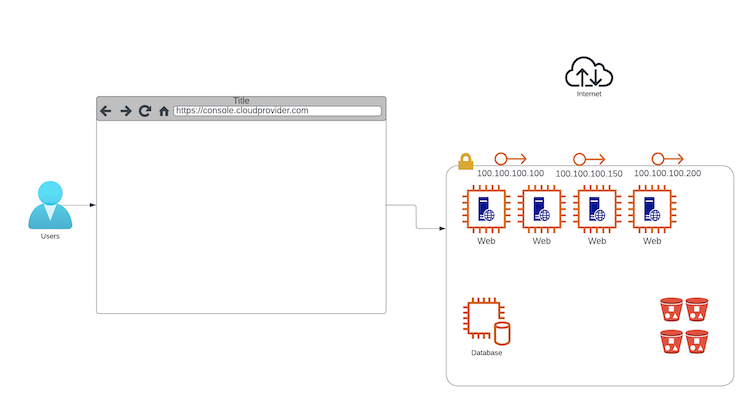
Things keep growing, and now you need some extra Web servers, IP addresses, BGP for routing and some storage buckets. You keep adding those.
Business just grows, which makes it all very happy, and before you know it, you have 50 servers, each with a different critical job, lots of IPs, and some complex networking.
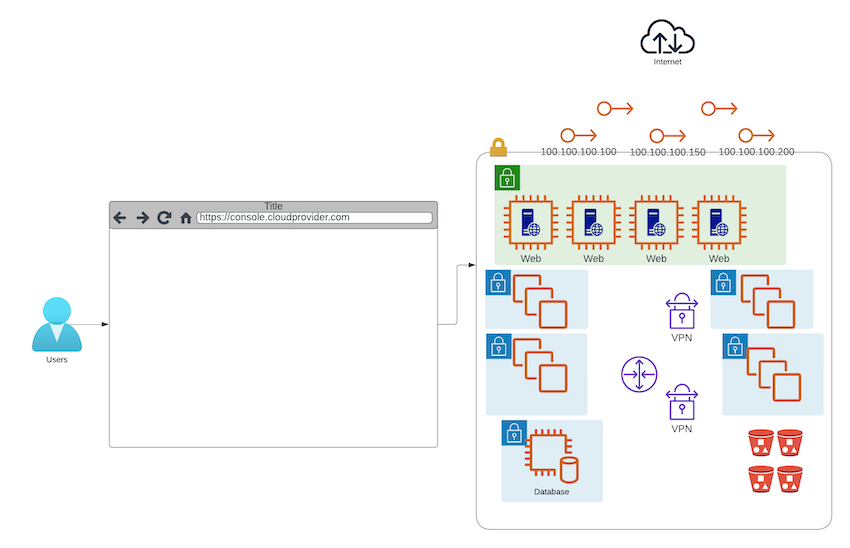
Of course, you are pretty proud of yourself, as you should be.
One day, the CEO calls you into their office. You are confident that this will be another good conversation, considering how well things are going. You walk in, and the CEO says, "I just got off the phone with my peer, who runs another online business. They had an issue, had to redeploy everything, and were down for 4 days, and even then they are not 100% sure they got it all back exactly the way it was before. It nearly put them under. I am sure you are doing a great job, we wouldn't be anything like that. If our whole infrastructure disappeared right now, how long would it take you to get us back up and running? An hour or two? Not more, right?"
After you are done with the cold sweat, you realize that you have no idea how long it would take.

Sure, business is fine now, but one bad day could destroy everything. You haven't built a Web-scale infrastructure; you have handcrafted an irreplaceable work of art. Art is beautiful, but it isn't what you want to bet your business on, unless you're the Louvre.
How do you solve this problem? What is the method for being able to respond to your CEO, "Sure, 1-2 hours should do it just fine, and it will be identical"?
On your first attempt, you just write everything down. Maybe you already did that. You take an Excel spreadsheet or Google Sheet, and list every single resource you deploy, and how it is configured. You list disk sizes and network configurations and IP addresses, load balancers and firewalls and CDNs and S3 buckets. You list everything.
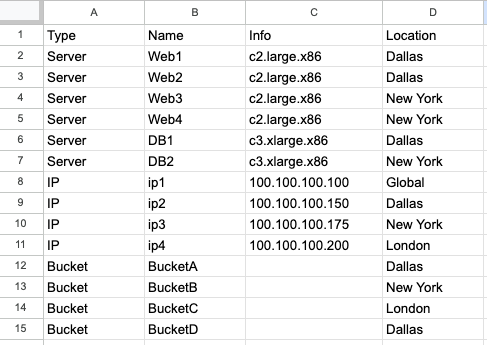
This is, largely, how things were done for many years at IT organizations. Once they reached a certain size, they probably had a somewhat more structured asset tracking system, but that was it.
What this does do is (mostly) ensure that you know what is out there, so that you can recreate it if needed. It will be a slow, manual, labourious process, but the knowledge is there. This, of course, is worlds better than having to rebuild from memory and hope you get it right.
As you complete this long process, a nagging worry starts to creep in. How do you know that this is up to date? Two weeks after you finished it, did you, or someone else on your team, deploy or change something? How do you know that you didn't miss anything?
Then you begin to realize that things do drift on their own, not just because someone changed something.
Beyond that, how do you know, really know, that you captured everything? Does your
row for server webprod225 have absolutely everything? Or are there some pieces
not recorded? Can you guarantee it?
While you start to worry more about these, your annual budget comes through, and the CEO has approved your team expansion. Gratefully, you hire two more infrastructure engineers and begin to train them.
As you show them your entire inventory, both you and they realize that your method of documenting is very unique. It obviously is not the exact same method as whatever company they worked at prior to coming here. This makes for a pretty steep learning curve.
Of course, they are quite bright, so they ask you, "it looks like everything is in here, but is there an order of deployment?" Uh, oh. There is, but you didn't capture it! You can do it simply enough, but it is one more piece of information to maintain.
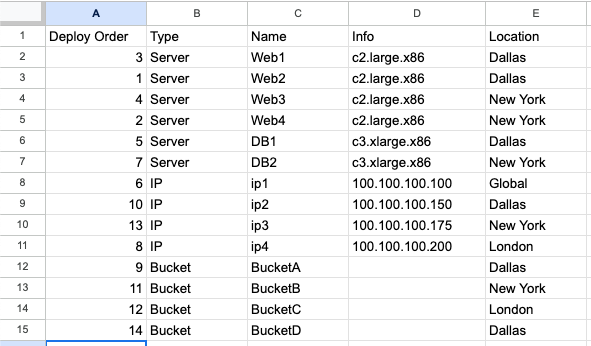
It looks like you made a big step forward, only to realize how far you still have to go!
As you take stock of your situation, you list the problems you are trying to solve, along with the requirements for solving them:
- Definition of your infrastructure, including everything needed to deploy it.
- Ability to deploy those definitions, reliably and repeatedly.
- Ability to define dependencies between resources, so that they are deployed in the correct order.
- Definition formats that are widely industry accepted, perhaps standard, so anyone can read them.
If you take a step back, you realize that what you are describing is code. Software code in agreed-upon languages has those characteristics.
- You define everything needed to build and run that software; if you miss anything, it will not build or run.
- You can build and run that software, reliably and repeatedly.
- You can define dependencies between the components of that software, so that they are built and run in the correct order; indeed, without them, you cannot run it.
- You write the software in well-known languages, such as C, Go, Java, Python, etc.
What you are looking for, then, is a way to define your infrastructure in code, with that code being usable to deploy and run your infrastructure.
This, then, is infrastructure-as-code.
Your process is straightforward:
- Define all of your infrastructure in the preferred code language.
- Validate and, if possible, test your code.
- Plan the deployment, i.e. check what would change if you ran it.
- Deploy the infrastructure based upon the code you defined.
What languages can you use? There are many, but the most common are:
- Terraform. Terraform actually is a tool, used to plan and deploy infrastructure. It uses its own language, called HCL, to define infrastructure resources.
- Pulumi. Pulumi is a tool, like Terraform, but it uses standard languages, such as Python, Go, JavaScript, TypeScript and C#, to define the infrastructure.
- Cloud-provider-specific languages, such as:
- CloudFormation. CloudFormation is a tool, used for AWS only, which uses its own JSON format, to define the infrastructure.
- Azure Resource Manager. ARM is a tool, used for Azure only which it uses its own JSON format, to define the infrastructure.
- Google Cloud Deployment Manager. GCDM is a tool, used for GCP only, which uses its own YAML format, to define the infrastructure.
Cloud-provider-specific ones, like CloudFormation, ARM and GCDM, are used directly with the specific cloud. Terraform and Pulumi, on the other hand, have plugins, called "providers", to enable their interaction with a broad range of cloud providers.
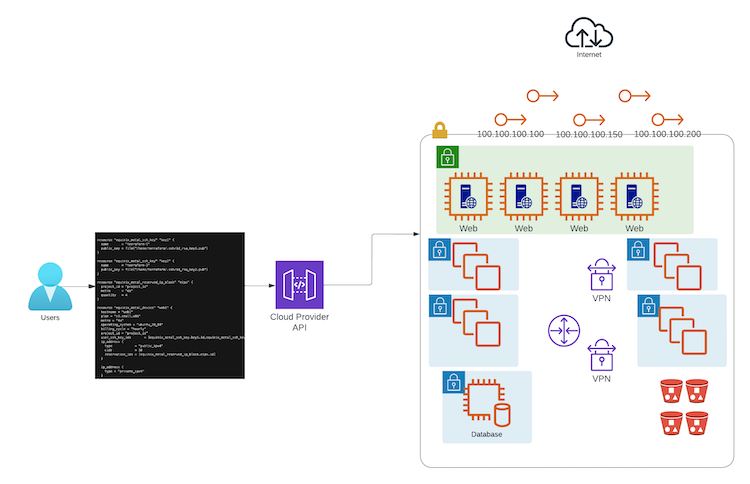
In order to make this practical, let's look at a sample IaC configuration for deploying some infrastructure on Equinix Metal using Terraform.
We won't go into installing Terraform, initialization, plan and deploy; a great example for that can be found in the Equinix Metal Developer Guides. We will focus just on the resources in the file.
resource "equinix_metal_ssh_key" "key1" {
name = "terraform-1"
public_key = file("/home/terraform/.ssh/id_rsa_key1.pub")
}
resource "equinix_metal_ssh_key" "key2" {
name = "terraform-2"
public_key = file("/home/terraform/.ssh/id_rsa_key2.pub")
}
resource "equinix_metal_reserved_ip_block" "eips" {
project_id = "project_id"
metro = "da"
quantity = 4
}
resource "equinix_metal_device" "web1" {
hostname = "web1"
plan = "c3.small.x86"
metro = "da"
operating_system = "ubuntu_20_04"
billing_cycle = "hourly"
project_id = "project_id"
user_ssh_key_ids = [equinix_metal_ssh_key.key1.id,equinix_metal_ssh_key.key2.id]
ip_address {
type = "public_ipv4"
cidr = 30
reservation_ids = [equinix_metal_reserved_ip_block.eips.id]
}
ip_address {
type = "private_ipv4"
}
}
resource "equinix_metal_device" "web2" {
hostname = "web2"
plan = "c3.small.x86"
metro = "da"
operating_system = "ubuntu_20_04"
billing_cycle = "hourly"
project_id = "project_id"
user_ssh_key_ids = [equinix_metal_ssh_key.key1.id,equinix_metal_ssh_key.key2.id]
ip_address {
type = "public_ipv4"
cidr = 30
reservation_ids = [equinix_metal_reserved_ip_block.eips.id]
}
ip_address {
type = "private_ipv4"
}
}
resource "equinix_metal_device" "web3" {
hostname = "web3"
plan = "c3.small.x86"
metro = "da"
operating_system = "ubuntu_20_04"
billing_cycle = "hourly"
project_id = "project_id"
user_ssh_key_ids = [equinix_metal_ssh_key.key1.id,equinix_metal_ssh_key.key2.id]
ip_address {
type = "public_ipv4"
cidr = 30
reservation_ids = [equinix_metal_reserved_ip_block.eips.id]
}
ip_address {
type = "private_ipv4"
}
}
resource "equinix_metal_device" "db1" {
hostname = "db"
plan = "c3.large.x86"
metro = "da"
operating_system = "ubuntu_20_04"
billing_cycle = "hourly"
project_id = "project_id"
user_ssh_key_ids = [equinix_metal_ssh_key.key1.id,equinix_metal_ssh_key.key2.id]
}
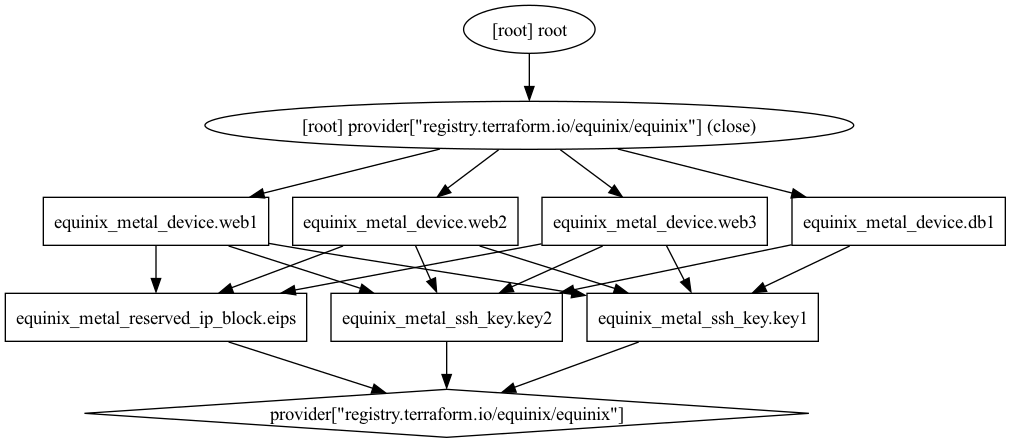
Let's look at what we have defined.
First, we defined two SSH keys, key1 and key2. These are used to access the servers.
resource "equinix_metal_ssh_key" "key1" {
name = "terraform-1"
public_key = file("/home/terraform/.ssh/id_rsa_key1.pub")
}
resource "equinix_metal_ssh_key" "key2" {
name = "terraform-2"
public_key = file("/home/terraform/.ssh/id_rsa_key2.pub")
}
Note that they have unique names in Equinix Metal, the name field, and that their public keysm in the public_key field, are taken from local files.
Next, we defined a block of IP addresses, which we will use for our servers.
resource "equinix_metal_reserved_ip_block" "eips" {
project_id = "project_id"
metro = "da"
quantity = 4
}
Notice that these IPs are in the Equinix Metal metro da, which is Dallas, and that
we asked for 4 of them.
Finally, we defined 4 servers, web1, web2, web3 and db1. The first three are
our public facing Web servers, and the last is the database server backing them.
The Web servers are nearly identical, so let's look at one of them:
resource "equinix_metal_device" "web1" {
hostname = "web1"
plan = "c3.small.x86"
metro = "da"
operating_system = "ubuntu_20_04"
billing_cycle = "hourly"
project_id = "project_id"
user_ssh_key_ids = [equinix_metal_ssh_key.key1.id,equinix_metal_ssh_key.key2.id]
ip_address {
type = "public_ipv4"
cidr = 30
reservation_ids = [equinix_metal_reserved_ip_block.eips.id]
}
ip_address {
type = "private_ipv4"
}
}
We defined everything Equinix Metal needs to deploy it: the hostname, the plan, the metro, the operating system, the billing cycle and the project ID.
More interestingly, notice that we told it to use the user ssh keys we defined above:
user_ssh_key_ids = [equinix_metal_ssh_key.key1.id,equinix_metal_ssh_key.key2.id]
These actually reference the IDs of the keys, which are generated when the keys are created. This, in turn, tells Terraform to create a dependency from the servers on the keys. Terraform will ensure that the keys are created before the servers are, and use their IDs when creating the servers.
Finally, we told it to use a public IP address, with a /30 CIDR block, as the public IP
of the server, from the block we created earlier:
ip_address {
type = "public_ipv4"
cidr = 30
reservation_ids = [equinix_metal_reserved_ip_block.eips.id]
}
This, too, depends on the block being created first, and Terraform will ensure that it is.
We can run the above as many times as we want. Every time it will either create the 2 ssh keys, 1 IP block, and 4 servers, or ensure that they are configured as we defined them. Even if someone changes them using the Equinix Metal CLI or Web UI, Terraform will detect the changes and revert them to the desired state.
We have declared the dependencies between the resources, and Terraform has ensured that these all are in place and valid.
Finally, we have used a well-defined and understood language. We can hire anyone with experience in the Terraform tool and, by extension, the HCL language, and they will be able to understand our definitions quickly and easily.
Finally, we can track all past, present and future states, the same way we do with all software: we can check it into software version control systems, like git.
Infrastructure-as-Code is our way of defining our infrastructure in a way that is reliable, repeatable, understandable and auditable.
IaC lets us sleep much more soundly at night.

You may also like
Dig deeper into similar topics in our archives
Configuring BGP with BIRD 2 on Equinix Metal
Set up BGP on your Equinix Metal server using BIRD 2, including IP configuration, installation, and neighbor setup to ensure robust routing capabilities between your server and the Equinix M...
Configuring BGP with FRR on an Equinix Metal Server
Establish a robust BGP configuration on your Equinix Metal server using FRR, including setting up network interfaces, installing and configuring FRR software, and ensuring secure and efficie...

Crosscloud VPN with WireGuard
Learn to establish secure VPN connections across cloud environments using WireGuard, including detailed setups for site-to-site tunnels and VPN gateways with NAT on Equinix Metal, enhancing...

Deploy Your First Server
Learn the essentials of deploying your first server with Equinix Metal. Set up your project & SSH keys, provision a server and connect it to the internet.

Ready to kick the tires?
Use code DEPLOYNOW for $300 credit