- Home /
- Resources /
- Learning center /
- What is Kubernetes...
What is Kubernetes?
The hottest technology for operations in years, but what is it?

On this page
What is Kubernetes?
![]()
If you are in the technology operations or application development space at all, you haven't missed hearing about Kubernetes.
What is it? And more importantly, why does it matter?
Most people will explain Kubernetes in terms of containers, and Google and Borg, and Docker, and yaml and all sorts of really interesting technologies. And those are interesting; we love them.
But none of those explains what Kubernetes is. We are going to do that for you.
Application management process
Let's take a step back from all of the interesting and cool tech terms, and focus on what applications and infrastructure teams do.
The general process for building and operating software is called the software development lifecycle (SDLC). It typically looks like this:
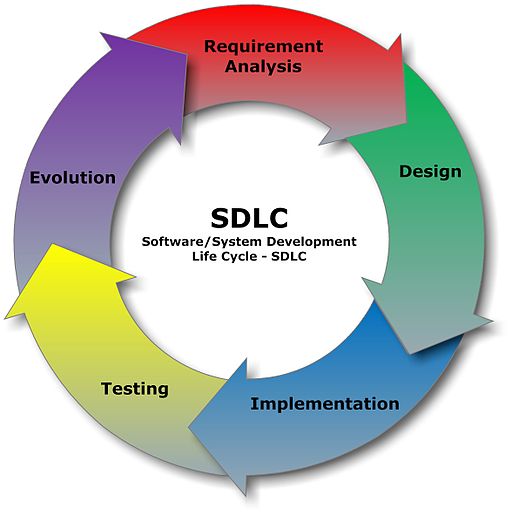
For our purposes, we have simplified it and focused only on the parts that are relevant to our discussion:
- Decide to build software, determine what features it needs
- Build the software
- Package it
- Deploy it
- Configure it
- Determine updates: bug fixes, feature additions and improvements
- Return to step 2
Obviously, the above does not fit the standard SDLC, but the cycle that you see is similar to what pretty much every software owner and manager does. Whether you are just one person managing a single open-source product all the way up to the largest Fortune 500 organization, this process is pretty much the same. Sure, a two-person SaaS business has both people do it all, and the number of approvals required is just one, with the budget in the thousands per year, while the largest multinational has teams for each step and budgets in the many millions, but both are trying to do the same basic process.
It turns out that for most of the steps, there are one or more agreed ways to do it, unofficial (and sometimes official) standards. Gantt charts for project planning, ITIL for descriptions of processes, Jira and its competitors for tracking issues and features, etc.
Existing deployment processes
The actual deployment process itself consists of just 3 steps:
- Package
- Deploy
- Configure
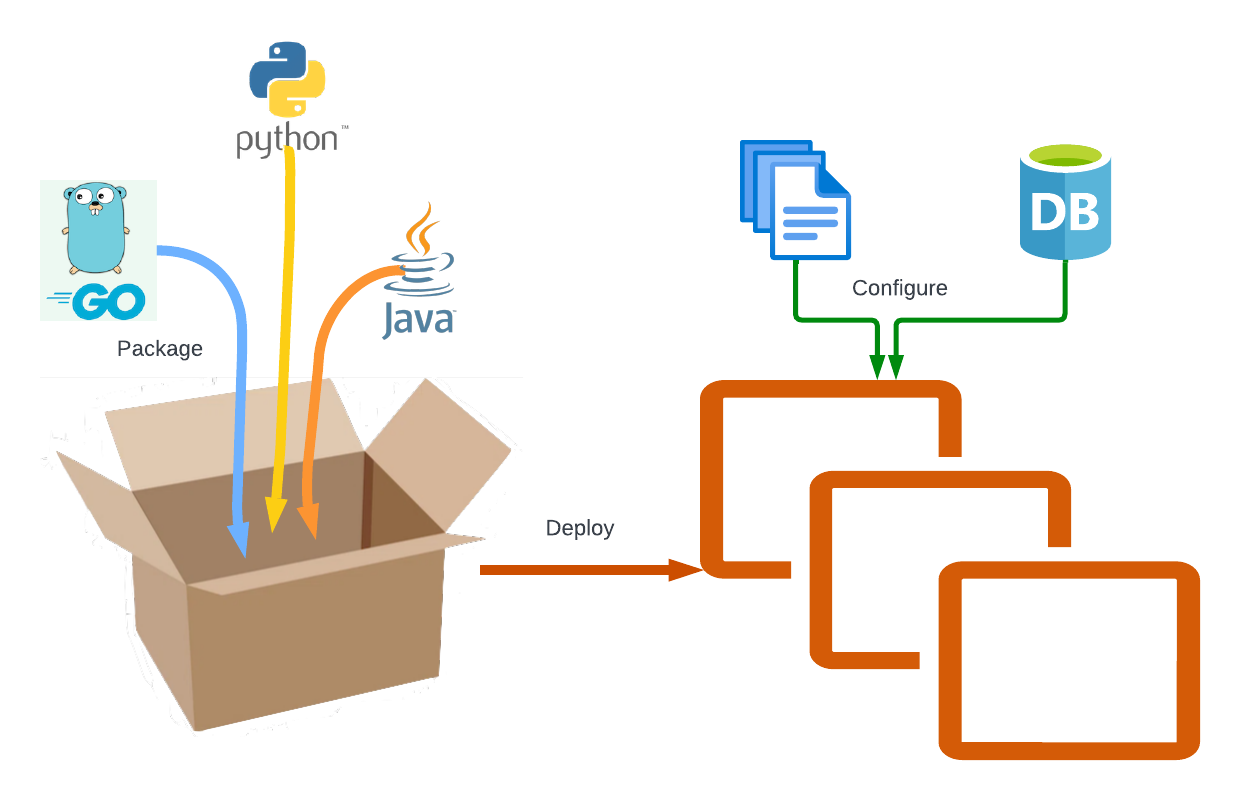
This process has been a wild west for decades. Here is a list of just a few of the dozens of ways we have seen people package, deploy and configure software:
- zip files, extracted by an operations team onto production with configuration in Word docs
- jar files (for Java), installed by ansible onto production with configuration in XML
- jar files, installed by Chef, configured to extract metadata from NFS shares and secrets from Vault
- self-extracting Windows exe files, configured via environment variables set by the ops team
- executable binaries, stored on an SMB folder, each with its own markdown describing how to deploy it, with secrets entered manually by an ops team
- compiled binaries, configured and deployed using a multi-million-dollar custom-built system written in shell and Perl
We could keep going for pages.
The important point is that every single organization has the exact same problems - package, deploy, configure applications - and yet just about every single organization does it in its own unique way.
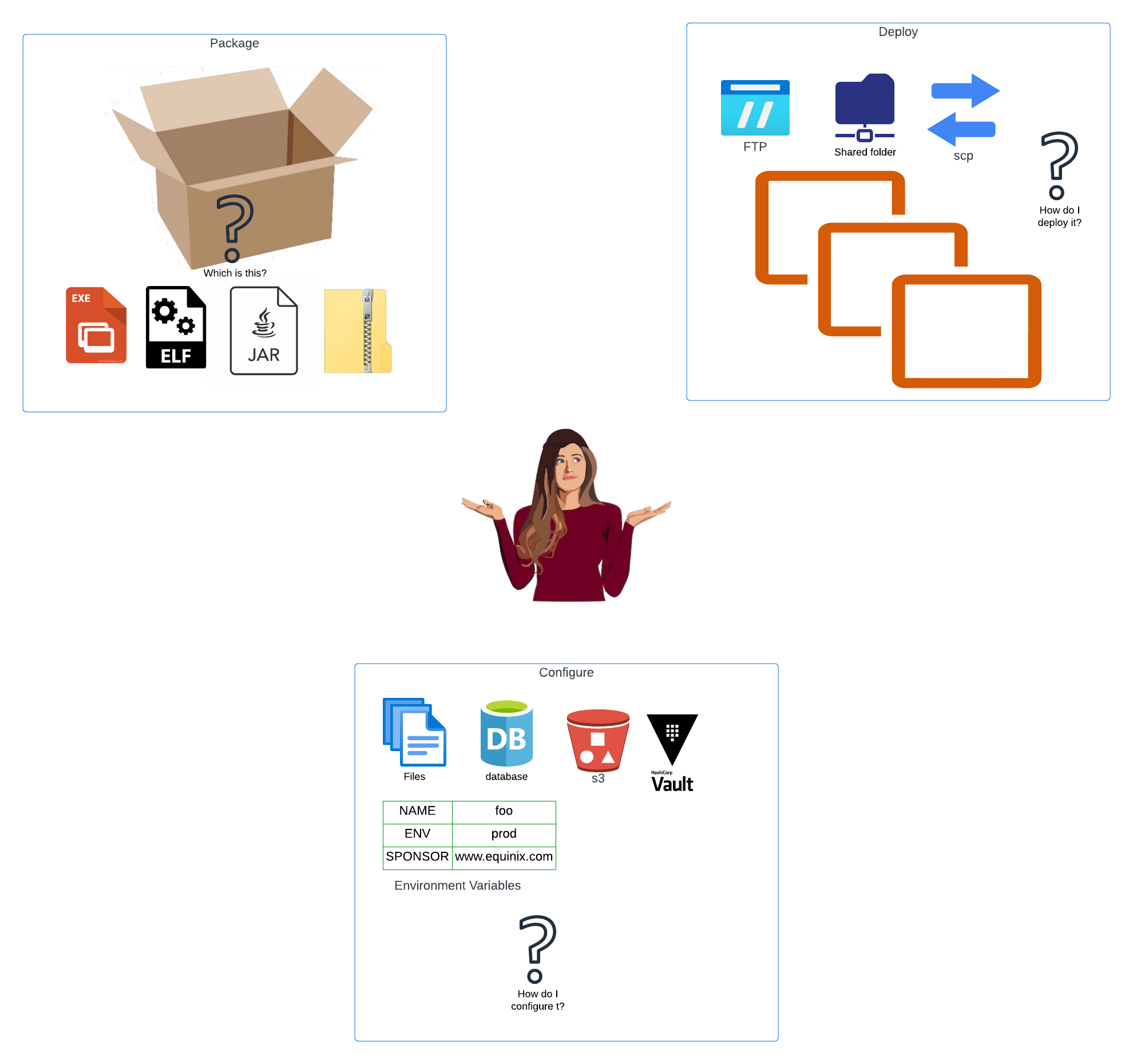
The costs of this are enormous.
- Every organization needs to build its own deployment process and, if big enough, systems.
- Every new engineer - application development, infrastructure, operations, security & compliance - needs to learn the new system, with the entire learning curve that entails.
- Every error requires an expert on just your systems and processes, who understands those, to work it through.
- The maintenance and improvements of your system are a cost borne by you and you alone.
The irony is that the vast majority of deployments largely can be described by just two scenarios:
- Deploy X copies of my software package
- Deploy one copy of my software package on every server
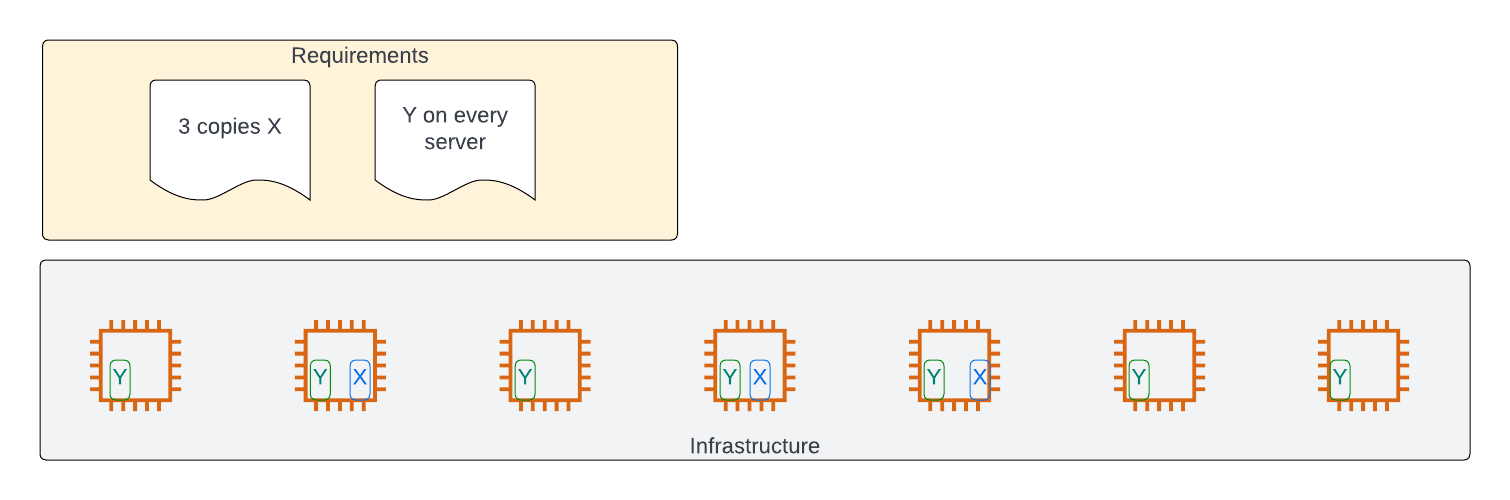
If you add a few modifiers, almost every single permutation in common use is covered:
- restrict which servers it runs on (by name, by location, by capabilities)
- control how it restarts and replaces
- determine how it co-exists with other software or copies of itself
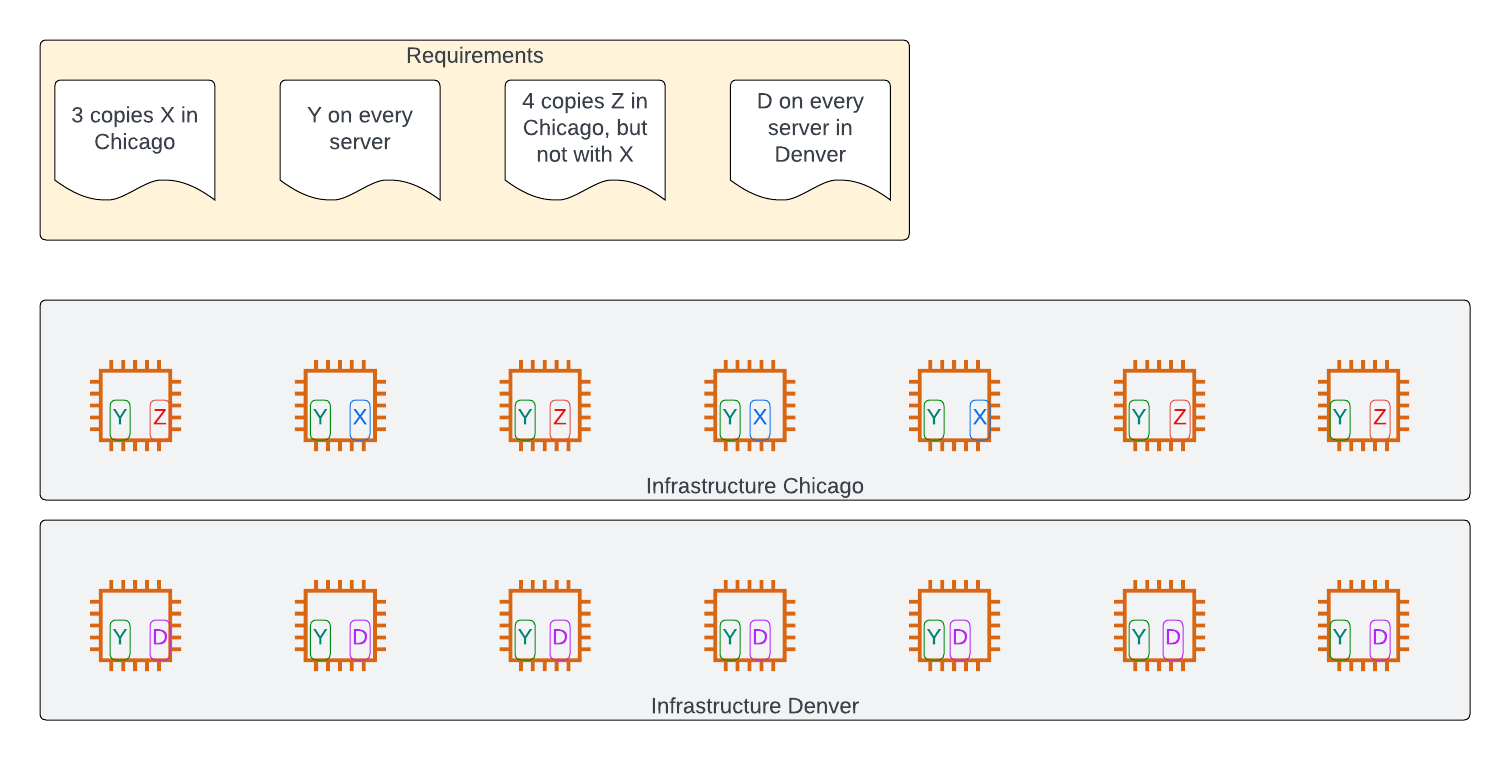
On top of the above, you need a way to set:
- configuration information
- secrets
I do not doubt that some readers could describe a scenario that doesn't quite fit into the above, but also that it is fairly rare and unique.
Setting standards
Well, if the overwhelming majority of software deployment could be described by the above few scenarios and configuration changes, why can we not have a standard, common, agreed way of describing it?
How hard would it be for both the two-person SaaS software company and the largest multinational to use the same method to describe cases like:
- Deploy three copies of my software in each of us-east and eu-west, ensuring that no two copies run on the same host, and configuring each to have a common set of 6 environment variables, plus one that is set to the hostname and one to the region.
- Deploy one copy of my software on every server worldwide, running with root privilege.
- Deploy six copies of my software, ensuring that they run only on servers that have Nvidia GPUs (it is the age of AI, after all) and at least 256GB of memory.
In other words, couldn't we all have an agreed way to describe this:
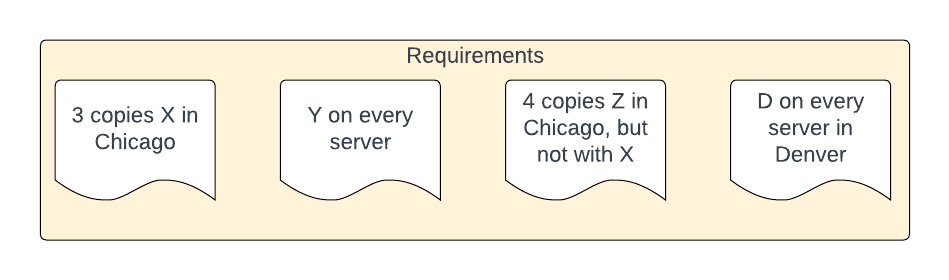
What we are looking for is a descriptive language, one tailored to our common deployment scenarios, to cover:
- software deployment rules - how many copies, how to deploy them, where they run
- software deployment configuration - what filesystems to make available, how to provision secrets, setting environment variables
All that is missing is a standard way of packaging applications.
Application packaging and distribution
As we saw above, there are uncountable ways of packaging software and distributing it. You can use zip files and place them on NFS shares; you can email them (yes, I really saw a company do that); you can use compiled binaries placed in an artifact repository; you can use exe files on Windows SMB shares; you can use tar.gz files on an ftp, sftp or scp location; we can keep going.
To round out our picture, we need a standard package for applications, and a standard distribution method for applications.
Enter Docker.
When Docker burst onto the scene, as its reincarnation from dotCloud, it brought containers to the masses of application engineers. What containers actually are matters less for our purposes; this might very well be the first article about Kubernetes that says containers matter less, but we stand by it.
The most important innovations from Docker were packaging and distribution.
Application packaging
Docker standardized and popularized a method for packaging files. Like any packaging system, such as zip or tar.gz, these packages include one or many files and directories, all laid out like in a filesystem.
In addition, Docker images contain layers, metadata about how the files should be used, for example, which file in the package is the software to run, or entrypoint, default environment variables to set, and a whole host of other information.
They eventually evolved to include the ability to contain or reference images for different operating systems or CPU architectures, and, more recently, software attestation information such as Software Bills of Materials (SBoM).
They inherently include a reference to the data they contain, by having every part of the image's name itself be a hash of the data, providing both much greater efficiency - why download something you might already have - and security - if the contents changed, you would know it. This is known as Content Addressable Storage (CAS), and is a subject for another day.
The most important part about Docker images is that they standardized the packaging of software in a universally-accessible, more resistant to spoofing, and more efficient to distribute format.
All of this was later placed under the non-profit Linux Foundation, the Open Container Initiative (OCI). The specification for images can be found here.
Software distribution
Last, we need to resolve distribution. Having a standard way to describe how to run software, how to configure that software, and how to unpackage that software, ultimately is of limited usage of you do not have a standard way to distribution that software.
Along with an innovative packaging format, Docker created an innovative distribution protocol. This protocol determines how services, called registries, can distribute images efficiently, how they are referenced, how authentication and authorization are handled, and the entire communications process.
This, too, became part of OCI, as the OCI distribution specification.
Multiple open-source and closed-source implementations of the distribution spec are available. Docker's own registry and Harbor stand out in open source, while closed source include jfrog artifactory, generic SaaS solutions such as Docker's own (and the very first) Docker Hub and Quay, and cloud providers' solutions, often tailored at their own compute offerings, such as Amazon Web Services' Elastic Container Registry and Azure's Azure Container Registry.
Tying it all together
We now have standard formats for:
- packaging software, courtesy of Docker and then OCI
- distributing software, courtesy of Docker and then OCI
- describing the rules for deploying software, courtesy of Kubernetes
- configuring the deployed software, courtesy of Kubernetes
We have a standard for the previously bespoke, or custom, practices that organizations spent sometimes vast sums determining and building out in their own custom way.
So is that it?
Is Kubernetes nothing more than a specification, a standard way to describe how to deploy and configure software, covering the vast majority of all use cases. Yes!
Let's repeat that. All of this fancy Kubernetes, the conferences, the hype, the deployments, the ecosystem... Kubernetes is nothing more than a specification, a standard way of describing how to deploy and configure software, that covers almost all use cases.
And that little is worth so much.
- No more building custom deployment processes.
- No more spending millions building custom deployment systems.
- No more complex multi-month learning curve for new employees.
- No more debugging opaque deployment systems understood by 3 people worldwide.
With standards in place, all sorts of additional tooling can grow around it, like security scanners and policy engines and approval pipelines and anything else we can think of, and much more that we have not yet.
Kubernetes matters because it standardizes processes and specifications across organizations that were expensive and custom before.
What about that software?
We might have glossed over one small thing.
Specifications are great, but you need software that implements that specification.
When someone says, "we are running Kubernetes", they likely mean, "we deploy and configure our software using the Kubernetes specification, and we use some software that implements that specification."
Kubernetes also is a freely downloadable open source reference implementation of that specification, available on the same Kubernetes site as the specification.
Because it is a specification, that reference implementation isn't the only verion available. You can get:
- Open source lightweight k3s from Rancher
- Enterprise Rancher Kubernetes Engine
- Managed Amazon Web Services Elastic Kubernetes Service
- Managed Google Kubernetes Engine
And many more.
Summary
Kubernetes is a specification for standardizing describing how to deploy and configure software, built on the standard packaging and distribution specifications from Open Container Initiative.
It also is a reference implementation of the same specification.
It matters because it takes what previously was expensive and custom per organization and standardizes it. You don't build your own servers, chairs or doors; why build your own software delivery system?
Last updated
07 August, 2024Category
Tagged
ArticleYou may also like
Dig deeper into similar topics in our archives
Configuring BGP with BIRD 2 on Equinix Metal
Set up BGP on your Equinix Metal server using BIRD 2, including IP configuration, installation, and neighbor setup to ensure robust routing capabilities between your server and the Equinix M...
Configuring BGP with FRR on an Equinix Metal Server
Establish a robust BGP configuration on your Equinix Metal server using FRR, including setting up network interfaces, installing and configuring FRR software, and ensuring secure and efficie...

Crosscloud VPN with WireGuard
Learn to establish secure VPN connections across cloud environments using WireGuard, including detailed setups for site-to-site tunnels and VPN gateways with NAT on Equinix Metal, enhancing...

Deploy Your First Server
Learn the essentials of deploying your first server with Equinix Metal. Set up your project & SSH keys, provision a server and connect it to the internet.

Ready to kick the tires?
Use code DEPLOYNOW for $300 credit