- Home /
- Resources /
- Learning center /
- What is Disaster R...
What is Disaster Recovery?
Recovering from disasters, because life is inevitable

On this page
We all know what a disaster is: earthquakes, floods, fires, hurricanes, tornadoes, tsunamis, and so on. When disasters strike, we want to recover from them: rebuild the homes, replant the crops, and drain the fields.
To keep our legal eagles happy and avoid any misunderstandings, we state very clearly that this is not legal advice, and we are not advising you on how to prepare for hurricanes, earthquakes and other disasters.
The key to recovering from disasters is: have a plan.
Creating a plan
Your plan for each kind of disaster involves:
- Assessing the chances of it happening
- Understanding the impact if it does happen
- Preparing for how to recover from it, if it does happen
In some cases, you might simply accept the risk. For example, if you live in New York City, an area of solid bedrock, the risk of earthquake is so low that it might well not exist. On the other hand, if you live near the San Andreas Fault in California, ignoring earthquakes might not be the best policy. On the other hand, if you live in Florida, you might want to plan more for hurricanes and less for earthquakes.
Similarly, if the impact is likely to be very low, even if the chances of it are high, it isn't worth the effort to plan for it. If you run a cardboard box company that stores its inventory outdoors, then sudden rains can ruin your boxes (and business). Yet if you run a boat storage company, the same rains will impact you not at all, or perhaps at most flood the walkway to the boats for an hour.
Put in other terms, whether or not an event is a "disaster" depends entirely on your context.
Let's stick with the cardboard boxes for a minute. You are in Michigan, not the Sahara, so you have real risk for a rainstorm, and real impact from that storm. Now you want to plan for recovery. Your goal: ensure you can keep operating your business even if there is a torrential downpour.
The first thing you can do is rather obvious: build a roof.
Sometimes, that will be enough. However, sometimes you cannot build a roof, or the way that rains fall in your area means that no roof will be enough, or maybe roofs are extremely expensive in your area, and sometimes - not often, but not never either - the rain will ruin your inventory of boxes.
Another step you can take is to build a second yard, far enough away from the first that a single downpour is very unlikely to take out both yards. The second site also may be inconvenient for your customers, but you can bring in stock to the primary site when needed, and keep the secondary site as a backup. If the primary site is flooded in its entirety, customers may be willing to endure everything taking a little bit longer, just for a time, by accepting delivery from your second site.
You also can take out insurance. If you regularly store $300,000 worth of inventory in the yard, you get $300,000 of insurance. Just pricing out insurance is a great way to evaluate your risk. The insurance company is in the business of evaluating risk. If your premiums are high, it means the experts estimate the risk of loss is high; if they are low, it means the experts estimate the risk of loss is low. You can use their expertise to help you evaluate the expectation of loss.
Even if you do have insurance, you could be in trouble.
On Sunday, you have $300,000 of inventory in the yard. On Monday, you have a sudden downpour, and the entire inventory is ruined. If you are really lucky, by the end of the week the adjustor evaluates the damage, and you get an insurance payment 3 weeks later. That's 3 whole weeks where you had to turn customers away. Now you need to order $300,000 of inventory, which can take weeks (or more) to arrive.
You have been unable to serve your customers at all for three weeks, partially for another two, and wholly only in another four after that. For almost an entire three months, you have been unable to serve customers fully.
Are they still there? Have they moved elsewhere? Will they come back two months later? Is there a business left to save?
Truly planning to recover from a disaster means not only making good on your losses due to the disaster itself, but far more importantly, ensuring you can continue to serve your customers - and maintain or even grow your business - during the recovery period.
Disasters in the cloud
Having spent enough time on cardboard boxes, let's talk about how this applies to cloud services.

Generally speaking, sudden downpours are not an issue for your cloud services. You run your servers in a proper colocation site, and the colo provider is responsible for ensuring that the servers are kept dry and protected. However, disasters still can strike:
- Wide-scale flooding
- Earthquakes
- Massive power loss or connectivity loss
- Fires
While the loss of an entire colocation site is rare, it can happen. When it does, everyone will be scrambling to recover.
Did you notice that we are talking about major disasters that take down entire data centres or regions? We are not concerned with a single server or two suddenly giving up the ghost. That is a different category of problem: high availability, which is much easier to solve. No, we are concerned with the loss of an entire data centre, or even an entire region.
Just like our cardboard box supplier, you need to plan from several angles.
First, you should have your rather expensive computer gear insured, if you actually own it. Obviously, if it is a cloud provider who you pay by the hour, even with a multi-year commitment, you do not take ownership of the equipment, and thus will suffer no capital losses if the data centre is lost permanently. However, if you actually do have ownership, you should insure it.
Next, you need to plan for how to keep operating. Just like the cardboard box supplier, you need another location, far enough away to be isolated from whatever took out the first data centre. Plan for another data centre in another region, one that is highly unlikely to be affected by the same disaster. If you have a data centre in Ashburn, VA, setting up your secondary in Reston, VA, just a few miles away is not a good plan. Major floods or earthquakes in Ashburn are very likely to affect Reston as well. On the other hand, whatever upends Ashburn is far less likely to affect Secaucus, NJ, or Chicago, IL, or even San Jose, CA.
Why not across the world, then? Wouldn't London, UK or Tel Aviv, IL be even better? In some cases, that may work very well. But in many cases, you will run into two issues. First, the latency of service will be much higher. If the majority of your customers are in North America, then serving them out of London or Tel Aviv can lead to a slower experience; the same holds true in the reverse. Second, you may run into regulatory issues, serving and, more importantly, processing and storing data of customers across legal boundaries. Depending on your usage and customers, your Compliance officer is likely to have an opinion or two on the issue.
Disasters affect capacity
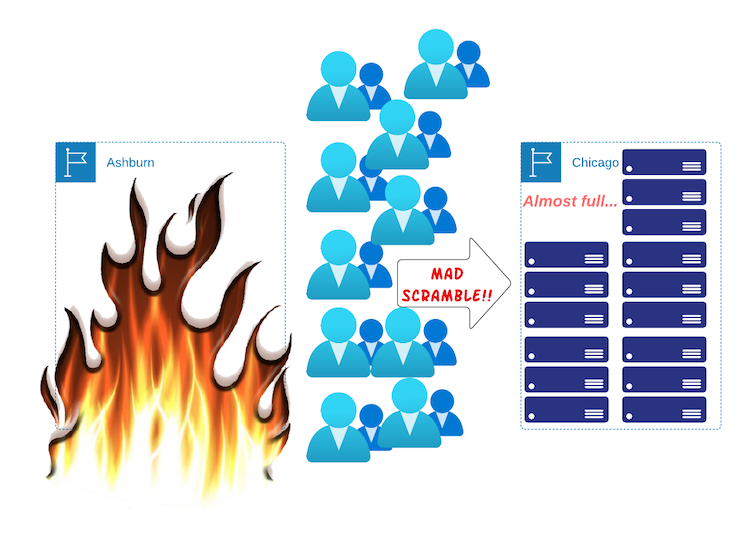
You have decided that, to protect yourself from disasters hitting Ashburn, VA, you want a site in Chicago, IL. Now, it isn't enough to just reserve the space. The cardboard box retailer cannot fill their entire supply of boxes in a single day. If you thought buying $300,000 in boxes takes time, try buying that much computer gear! It can take weeks or longer. Add in the crush of people who all are facing the same issue when that disaster took out Ashburn, and you are unlikely to see replacement equipment for quite some time.
This is true even in the public cloud. Sure, they have lots of capacity... now. But the moment that Ashburn goes down and everyone wants to deploy instances in Chicago, capacity likely will be hit very quickly. You don't want to be the one to get the "out of capacity" notice. This means you need to reserve sufficient capacity right now, when demand is normal.
Keep the plan ready to go
You have recognized you need an alternate location, you have reserved space and the processing power you need. That's it, a one-time thing, right? Unfortunately not. You need to ensure that your capacity in Chicago always is up to date. Ashburn likely is changing by the month, if not by the day. If you don't keep Chicago up-to-date, you will discover it cannot do its job, just when you need it most. The key to making that work is automation.
You have a pipeline to deploy infrastructure and services to Ashburn already. Maybe it is infrastructure-as-code, maybe it is old-school work orders, but there is some process. Make Chicago part of that process. If a deployment causes Chicago to be out of date, it just doesn't go through.
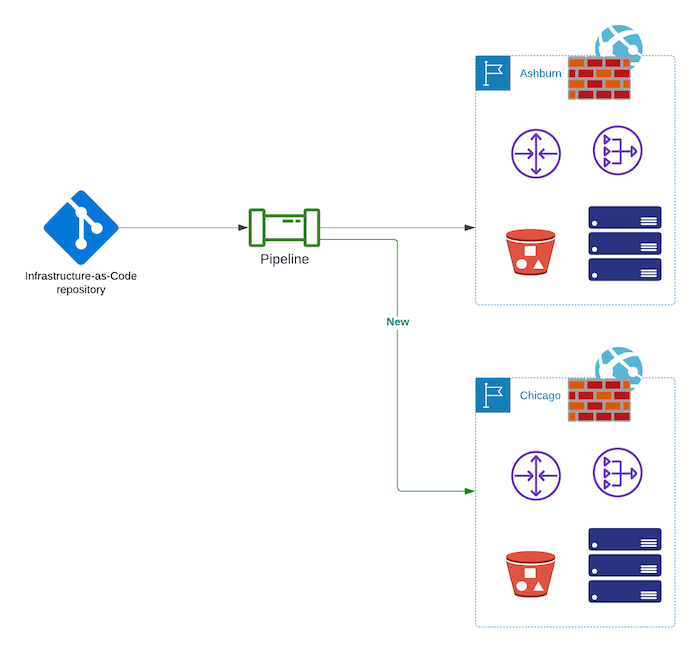
What about software and data? Without the right software running and the right up-to-date data, Chicago is as useful as a pile of bricks. You need to ensure that your software and data are up-to-date in Chicago, too. Again, the answer is automation.
You have a proper automated process, or pipeline, for deploying and keeping software up-to-date in Ashburn. Your Continuous Deployment
pipeline may be implemented in Jenkins, controlled by a jenkinsfile, perhaps GitHub Actions,
GitLab Pipelines or BitBucket Pipelines,
or it could be other systems, including your own bespoke one. Whatever process is used to deploy and update your software into Ashburn
automatically, should be configured to deploy and update the same software to your alternate site automatically.
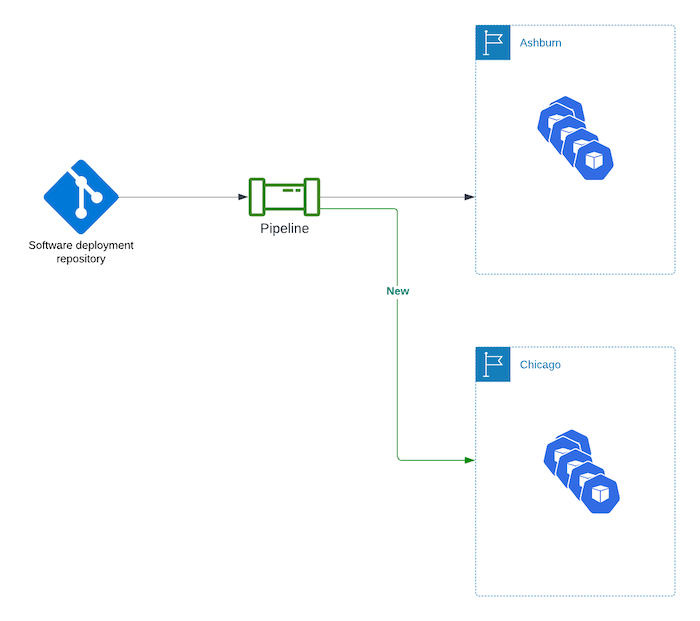
Don't forget the data
You're close to a proper disaster recovery plan: a secondary site, in a different region, which is kept up-to-date with the primary site. Time try it out.
You did everything in the plan; things are going swimmingly. One day, disaster strikes, and Ashburn goes away for a while. "No problem," you say, "let's switch to Chicago." You flip the switch, and... nothing happens. Why? For two reasons.
First your customers are still being processed in Ashburn (or trying to, since Ashburn is inaccessible), and you have no way to tell them to go to Chicago instead.
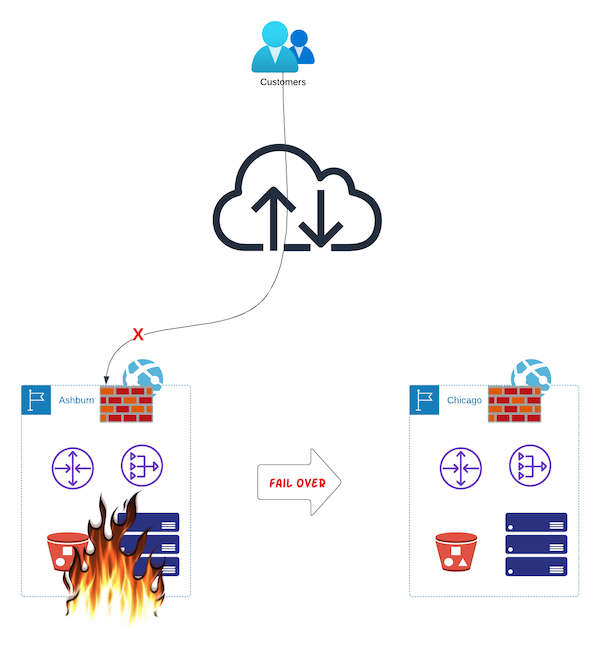
You can fix that by changing some DNS entries and waiting for caches to expire. Now your customers are going to Chicago.
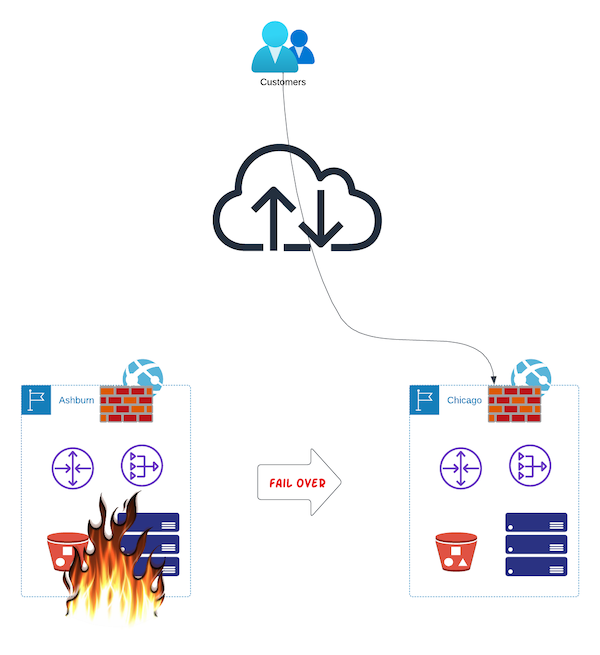
But still, nothing.
Their data still is in Ashburn. Even though they are being processed in Chicago, they are being processed with stale data. Until about 5 minutes ago, they did everything in Ashburn, including storing data. When you switched to Chicago, the processing moved over, but none of their data is there. Imagine you are a bank, customers log in and see $0 balance. That might be worse than being unavailable!
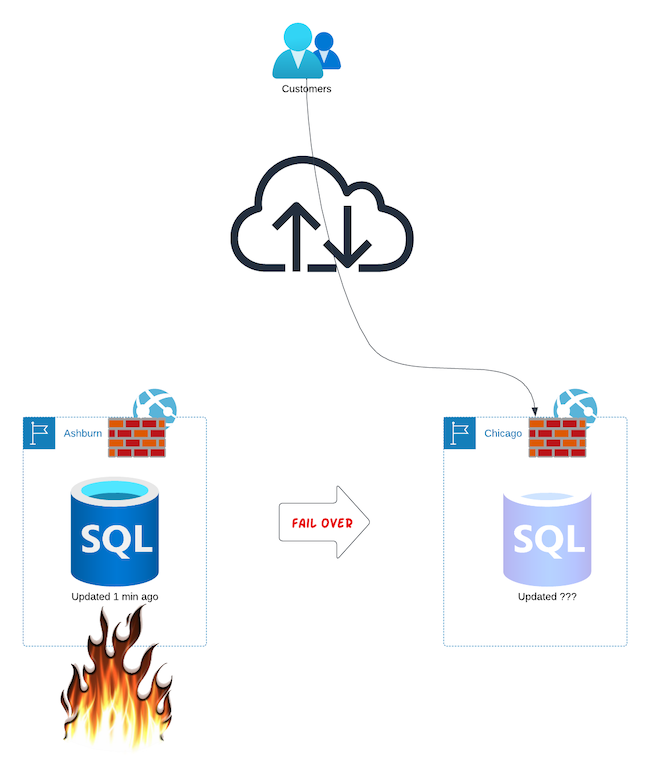
Your data wasn't part of your ongoing disaster recovery plan, and the migration itself wasn't part of your plan.
You need to ensure that the data is kept up-to-date in Chicago, just like the software. Your data is stored in one of several places:
- filesystems
- object stores (like S3)
- databases
If you are using filesystems, you need to set up replication between your sites. Wherever the data is being written, it needs to be replicated to your alternate site. You can do that either by having a separate process that replicates the data to the alternate site, or by using a filesystem that does it for you.
Similarly, if you are using object stores, you need to ensure that the data is replicated to the alternate site. As with filesystems, this can be done either by using a "synchronizer" process that replicates the data to the alternate site, or by using an object storage service that can handle replication.
Finally, let's look at databases. Almost every database includes replication as a feature. For example, the MySQL reference includes an entire chapter describing how to replicate, as do most other databases, open-source like MySQL and Postgres, and closed-source like Oracle and Microsoft SQL Server. NoSQL databases like Mongo, CouchDB and Cassandra also include replication as a feature. Indeed, in some cases, it is easier with NoSQL databases.
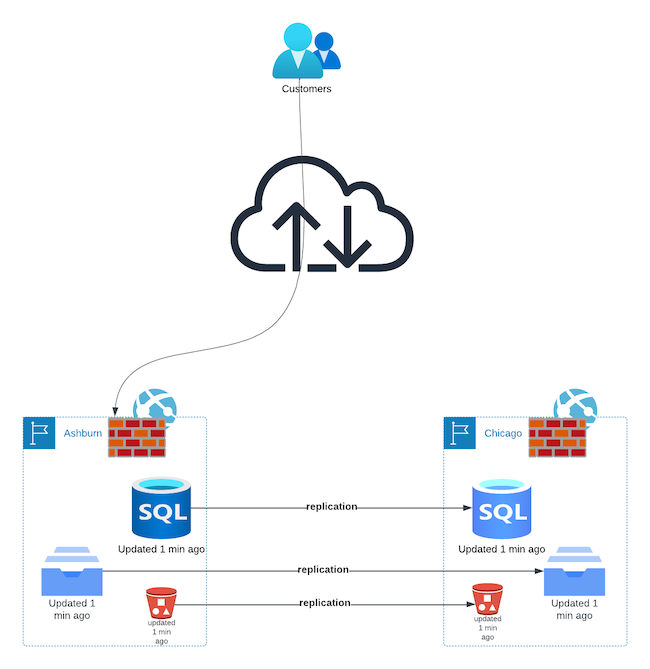
Does this solve the data issue? Not precisely. On Monday, Ashburn suffers a catastrophic event, so you switch to Chicago. Everything works fine for three days, when Ashburn comes back online. "Sounds great, let's switch back!" You do so, and... uproar! Once again, stale data. For three days, customers were being processed in Chicago, including all of their data. You have a great process for replicating all of your data - filesystems, objects, databases - from Ashburn to Chicago, but what about back the other way? And how do you reconcile that data with what is in Ashburn but out of date?
You need to plan for cutover not only from your "primary" location to alternates, but also how to cut back.
Test the plan
Finally there is the cutover process itself.
In addition to the DNS entries what else is there that has to change for customers to be processed properly in one site versus another? Are there email or ftp communications sites? What about customer support? Certificates? The list can be quite long. The key element is process. You need a clear, well-defined process for cutover, and you need to practice it. Without actually practicing it, you have no idea if the plan actually will work.
You need to practice it a lot.
You don't want the first time you try to switch sites to be the moment when you have no primary site. Instead, you want to do it when primary is doing just fine, and if the cutover fails, you can return to the primary immediately. One of the keys, if not the key, element to successful disaster recovery preparation is to practice it over and over and over when things are just fine. That way, when things are not fine, you know exactly what will happen.
Most organizations shy away from this. "Fail over now? During business hours? Why should we take that risk?" The answer is simple: because doing it now reduces dramatically the risk when a real disaster happens. You don't get disaster-resilient systems by planning for them, but by planning for and practicing them.
Conclusion
If you want to stay in business following a disaster that takes out a major site, you need to:
- Plan every step of the process.
- Automate as many of those steps as possible.
- Practice that cutover as often as possible, especially when things are fine.
These steps include advance preparation:
- Infrastructure deployment
- Software deployment
- Data replication - databases, filesystems, object stores
Disaster recovery itself:
- Traffic redirection
- Primary data enabling
- Support and other process direction
- Customer communication, if needed
Disaster recovery restoration:
- Traffic redirection
- Primary data enabling back to the original site
And above it all, process validation and testing, testing, testing!
No process ever will be 100% perfect, but you can get pretty close if you understand your risks, lay out your goals, define processes, automate everything, and practice, practice, practice.
* Plan image licensed under Creative Commons 3 - CC BY-SA 3.0; Attribution: Alpha Stock Images; Original Author: Nick Youngson
You may also like
Dig deeper into similar topics in our archives
Configuring BGP with BIRD 2 on Equinix Metal
Set up BGP on your Equinix Metal server using BIRD 2, including IP configuration, installation, and neighbor setup to ensure robust routing capabilities between your server and the Equinix M...
Configuring BGP with FRR on an Equinix Metal Server
Establish a robust BGP configuration on your Equinix Metal server using FRR, including setting up network interfaces, installing and configuring FRR software, and ensuring secure and efficie...

Crosscloud VPN with WireGuard
Learn to establish secure VPN connections across cloud environments using WireGuard, including detailed setups for site-to-site tunnels and VPN gateways with NAT on Equinix Metal, enhancing...

Deploy Your First Server
Learn the essentials of deploying your first server with Equinix Metal. Set up your project & SSH keys, provision a server and connect it to the internet.

Ready to kick the tires?
Use code DEPLOYNOW for $300 credit