How to Build Network Services in the User Space
Why we decided to process packets outside the OS kernel and what we’ve learned doing it.
When writing an application that deals with transferring data between different nodes, be it an HTTP server or client, API gateways, storage services or something else, some kind of networking subsystem has to be involved. The data needs to be serialized and prepended with various packet headers in order to make sure it reaches its final destination on the other side of the service.
In Linux systems, it’s the OS that handles all the network-specific tasks, from encapsulating the application data into network protocol headers to directing data from received packets to the right applications. Application developers commonly offload all networking-related logic to the kernel, which is suitable for the vast majority of use cases. Dealing with the actual packets and encapsulation intricacies isn’t the problem your application needs to solve. There are, however, applications that need to handle packet processing at very high rates, and that is a challenge we have been working on as we develop our cloud-native network offerings.
Over the years, new protocols were invented, standardized and made it to a released kernel; more code was added. The more code we run in the packet processing logic, the longer it takes to process a packet. Being general-purpose, the Linux network stack has a whole bunch of features, which sometimes get in the way when you’re trying to optimize it for bulk packet forwarding. On top of that, because networking code lives in the kernel, any updates or extensions to the network stack might need a kernel upgrade.
We realized that if we wanted a fast, extensible and decoupled networking stack we would need to look for it elsewhere. As the title suggests, we went down the path of taking the kernel out of the picture for packet processing tasks and doing it all in the user space. In this article we’ll share some of what we have learned so far in our journey and highlight some of the tools we’ve been using to power the next generation of Equinix products.
More on networking:
- It Isn’t Magic, It’s TCP: Demystifying Networking for Developers
- Locking Down Your Cloud Network: The Basics
Before we get into the solution, let’s make sure you understand the two big reasons we think the Linux network stack wouldn’t be a sensible choice for our use case.
Reason 1: Packet Processing Overhead
Much has to happen before application data reaches the right process or is forwarded to the destination interface. On the ingress side (that is, receiving traffic), the packet is received by the network card. The network driver will usually interrupt the kernel so it knows there is a packet waiting to be processed. This interrupt causes the CPU to pause what it’s doing and go process that packet. This is called a “context switch.” The CPU then allocates a certain amount of memory and copies the packet data received from the NIC there. This part of the process is called SKB allocation, and it basically means that the kernel now has an internal structure to represent the packet.
The packet now sitting in memory is also parsed and filled with lots of metadata, which might be consumed by different parts of the kernel subsystems. Here we find references to the input interfaces, hashing value, tunnel keys and so on. As the packet moves up the processing chain, several operations are performed on it in order to determine where that data is supposed to go: either to a remote system (that is, to be forwarded) or to a local socket that is interested in packets matching certain criteria (a combination of address and port). Both forwarding and socket delivery also consume precious CPU time.
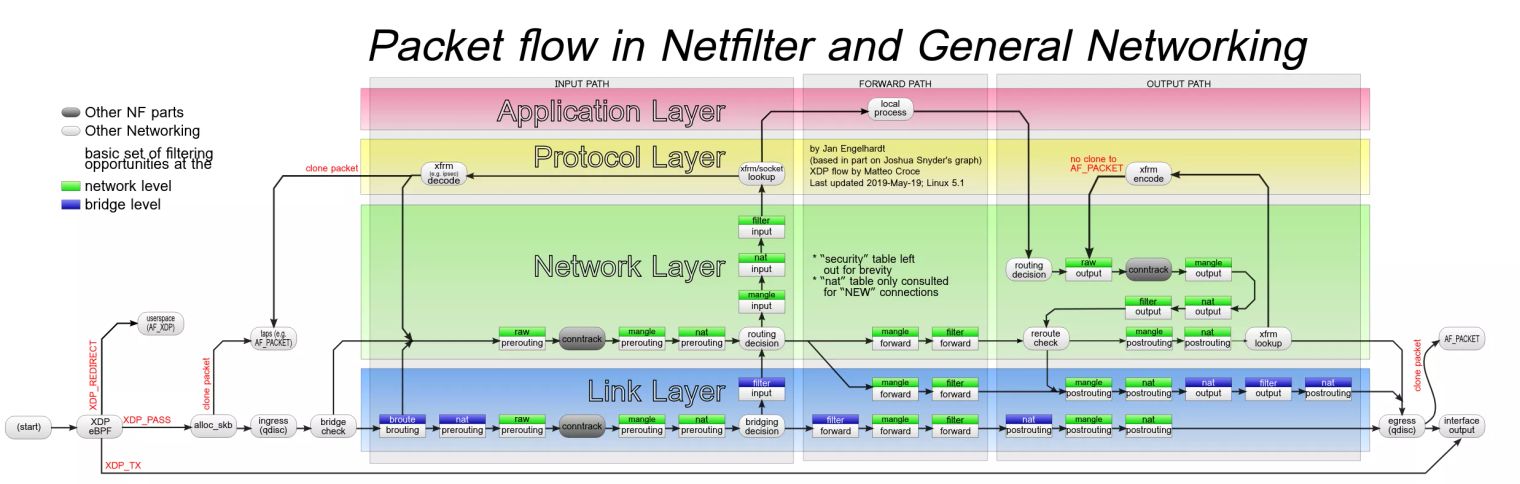
The long list of things that happen between packet arrival and packet forwarding or application delivery includes ingress queuing, route lookups, firewall filters, routing rules, socket matching, header rewrite, encapsulation, error handling and much more. A lot of CPU time is spent just figuring out what to do with a single packet.
This diagram should give you a good idea of the level of complexity involved:
{kind=link}
You can try to tune the system (use NAPI or GRO/GSO) or use lower-level sockets (such as AF_PACKET), but in most cases that is not enough (one exception being while getting data from XDP hooks or some zero copy mode supported on some socket families). A big part of the CPU time and effort is spent copying data from one memory block to another (from NIC to kernel, from kernel to application memory or egress NIC buffer). The same is true for data originated from an application and headed toward a remote system.
Reason 2: Upgrades
It’s natural to want to change a networking product to fit new use cases, fix bugs and support new features. If these new features had to go in the kernel code, keeping all that code up to date would be a lot of work. And releasing that code would be even more work, as the entire operating system would change as a result. On the other hand, if the thing that runs the product (like some process) is not tightly coupled to the thing that runs the thing (like the kernel), it is easier to upgrade one without changing the other. New functionality can go live faster and more smoothly.
Taking Packet Processing Over From the Kernel
Networking in the kernel is relatively simple. There are multiple ways one can influence the packet path in the kernel (like routes, IP rules, packet manipulation with TC, firewalls and so on) and lots of different customizations are possible. ARP, routing, ICMP handling and other control protocols are all implemented in the kernel out of the box. But this also means that if you want to take over a NIC from the kernel and handle packet processing yourself, you will likely need to do some extra work in order to speak fluent “networkish:” resolve MAC addresses, interpret and respond to ICMP messages, build and keep tables fresh and so on. That job is far from being straightforward.
When a Linux-based operating system boots up, it probes the devices connected to its motherboard. After discovering them, it loads a suitable driver (also called a kernel module) in order to use these devices. When the kernel discovers a network card, it loads a driver supported by that NIC, and the result is that the kernel can now use it to both receive and transmit packets. Ingress packets from the NIC will then follow the path along the networking subsystem that will decide whether to process that packet (deliver to a socket, forward it, handle control packets such as ARP/ND or ICMP) or drop it. Some NICs go even further and take over some extra work with offload capabilities.
But if we wish to set the kernel’s packet processing aside, we need to pull the NIC out of the kernel and use it directly from our application. This can be done by loading a passthrough-like driver for the NIC (the vfio-pci driver, for example). With these drivers, you could use the DPDK (Data Plane Development Kit) poll mode drivers to configure the NIC (and its queues) as well as accessing the packet descriptors on that device using DMA (Direct Memory Access), making packet access very fast. All the kernel knows is that there’s a PCI device—it doesn’t even know it’s a network card at this point—and doesn’t try to do anything related to networking at all.
Using DPDK
One popular use case for DPDK is on a virtual switch inside a virtualized or containerised system. Traditionally, these technologies rely on a host kernel to expose both hardware resources and networking connectivity. The networking connections of the guest systems would take the form of a virtual NIC plugged into a software bridge in the kernel or some other similar abstraction (macvlan, taps, etc). One problem here is that the host kernel becomes a bottleneck, handling packet forwarding for an increasing number of applications and guest systems.
A number of projects were born in the past few years that can address this shortcoming, and most of them consist of replacing the Linux host networking stack with a faster software bridge. “Faster” here really means just not trying to do everything that the kernel does, only the essentials; and doing them more efficiently. Examples of projects that use DPDK to enable fast packet processing include Snabb, OVS and FD.io (VPP). A more complete list of DPDK projects is available on the DPDK website.
Due to its wide range of protocols and a decent level of maturity, we chose VPP to be the underlying forwarding engine of our next-generation platforms. The sections that follow detail why we made this decision.
VPP
VPP is a high-performance packet processing stack. It was originally developed by Cisco and powers a fair amount of its product portfolio. This technology was open sourced, and it’s now maintained by the FD.io project.
It consists of breaking the packet processing steps into small pieces and joining those pieces together in what it calls a node graph. To process a packet, we walk a path through the node graph, depending on what’s in the packet, and when we get to the end we have done all the work that packet needs.
VPP grabs many packets at once (grouped in a vector) and instead of walking each of them one by one through all the work, it does one small piece of work on all the packets at once before moving to the next node in the graph. This is much more efficient on modern CPUs, which means we can process more packets with less CPU time. For a more detailed description of the technology refer to the official documentation.
In order to use VPP, you can either install it as a package or build it yourself from source.
Using VPP
If you’re familiar with configuring network equipment (hardware routers, switches) through a CLI, VPP has a CLI that can be used to manage its configuration. If you are more comfortable writing code, you can interact with VPP using its C or Golang APIs. VPP creates socket files that can be used to manage it on startup (cli.sock and api.sock) and the tools use those to communicate with it. Here is an example of using the CLI socket to connect to VPP:
$ vppctl -s /run/vpp/cli.sock
_______ _ _ _____ ___
__/ __/ _ \ (_)__ | | / / _ \/ _ \
_/ _// // / / / _ \ | |/ / ___/ ___/
/_/ /____(_)_/\___/ |___/_/ /_/
vpp# show interfaces
Name Idx State MTU (L3/IP4/IP6/MPLS) Counter Count
VirtualFunctionEthernet1a/6/0 1 up 9000/0/0/0 rx packets 62
rx bytes 7320
tx packets 5
tx bytes 606
drops 59
punt 1
ip6 62
VirtualFunctionEthernet1a/e/3 2 down 9000/0/0/0
local0 0 down 0/0/0/0
vpp#
As in any decent networking stack, VPP supports packet capture and counters, and will even tell you which nodes in the graph are being run and how often. These are very useful for debugging and troubleshooting.
Next, let’s take a quick look at some of the basic configurations we will often see in VPP instances.
Exposing NICs to VPP
As mentioned before, VPP uses DPDK libraries to manage NICs. Before starting VPP, we need to configure it to bind to the right interfaces. This can be done by either providing the interface PCI addresses in the configuration file (startup.conf) or by not specifying any interface and letting VPP take over all interfaces it can find. Refer to the DPDK section in the documentation for more info.
In this example, I am running VPP in a container, giving it two NICs by means of putting them in its container. VPP tries to bind to all interfaces, but that is fine, because the host won’t let it take over interfaces we haven’t explicitly allowed:
vpp# sh log
2023/09/29 09:21:10:028 notice vat-plug/load Loaded plugin: acl_test_plugin.so
2023/09/29 09:21:10:030 notice dpdk EAL: Detected CPU lcores: 56
2023/09/29 09:21:10:030 notice dpdk EAL: Detected NUMA nodes: 2
2023/09/29 09:21:10:030 notice dpdk EAL: Detected static linkage of DPDK
2023/09/29 09:21:10:030 notice dpdk EAL: Selected IOVA mode 'VA'
2023/09/29 09:21:10:030 notice dpdk EAL: No free 1048576 kB hugepages reported on node 0
2023/09/29 09:21:10:030 notice dpdk EAL: No free 1048576 kB hugepages reported on node 1
2023/09/29 09:21:10:030 notice dpdk EAL: VFIO support initialized
2023/09/29 09:21:10:030 notice dpdk EAL: Using IOMMU type 1 (Type 1)
2023/09/29 09:21:10:030 notice dpdk EAL: Probe PCI driver: net_iavf (8086:154c) device: 0000:1a:06.0 (socket 0)
2023/09/29 09:21:10:030 notice dpdk EAL: Failed to open VFIO group 142
2023/09/29 09:21:10:030 notice dpdk EAL: 0000:1a:06.1 not managed by VFIO driver, skipping
2023/09/29 09:21:10:030 notice dpdk EAL: Failed to open VFIO group 143
2023/09/29 09:21:10:030 notice dpdk EAL: 0000:1a:06.2 not managed by VFIO driver, skipping
2023/09/29 09:21:10:030 notice dpdk EAL: Failed to open VFIO group 144
2023/09/29 09:21:10:030 notice dpdk EAL: 0000:1a:06.3 not managed by VFIO driver, skipping
2023/09/29 09:21:10:030 notice dpdk EAL: Failed to open VFIO group 145
2023/09/29 09:21:10:030 notice dpdk EAL: 0000:1a:0e.0 not managed by VFIO driver, skipping
2023/09/29 09:21:10:030 notice dpdk EAL: Failed to open VFIO group 146
2023/09/29 09:21:10:030 notice dpdk EAL: 0000:1a:0e.1 not managed by VFIO driver, skipping
2023/09/29 09:21:10:030 notice dpdk EAL: Failed to open VFIO group 147
2023/09/29 09:21:10:030 notice dpdk EAL: 0000:1a:0e.2 not managed by VFIO driver, skipping
2023/09/29 09:21:10:030 notice dpdk EAL: Probe PCI driver: net_iavf (8086:154c) device: 0000:1a:0e.3 (socket 0)
The logs say that VPP was able to bind to two NICs: 0000:1a:06.0 and 0000:1a:0e.3. We can also check them with the show hardware-interfaces command:
vpp# show hardware-interfaces
Name Idx Link Hardware
VirtualFunctionEthernet1a/6/0 1 up VirtualFunctionEthernet1a/6/0
Link speed: 10 Gbps
RX Queues:
queue thread mode
0 main (0) polling
TX Queues:
TX Hash: [name: hash-eth-l34 priority: 50 description: Hash ethernet L34 headers]
queue shared thread(s)
0 no 0
Ethernet address e6:ff:30:5c:e3:65
Intel iAVF
carrier up full duplex max-frame-size 9022
flags: admin-up maybe-multiseg tx-offload intel-phdr-cksum rx-ip4-cksum int-unmaskable
rx: queues 1 (max 256), desc 1024 (min 64 max 4096 align 32)
tx: queues 1 (max 256), desc 1024 (min 64 max 4096 align 32)
pci: device 8086:154c subsystem 1028:0000 address 0000:1a:06.00 numa 0
max rx packet len: 9728
promiscuous: unicast off all-multicast on
vlan offload: strip off filter off qinq off
rx offload avail: vlan-strip ipv4-cksum udp-cksum tcp-cksum qinq-strip
outer-ipv4-cksum vlan-filter vlan-extend scatter rss-hash
rx offload active: ipv4-cksum scatter
tx offload avail: vlan-insert ipv4-cksum udp-cksum tcp-cksum sctp-cksum
tcp-tso outer-ipv4-cksum qinq-insert vxlan-tnl-tso
gre-tnl-tso ipip-tnl-tso geneve-tnl-tso multi-segs
mbuf-fast-free outer-udp-cksum
tx offload active: ipv4-cksum udp-cksum tcp-cksum multi-segs
rss avail: ipv4-frag ipv4-tcp ipv4-udp ipv4-sctp ipv4-other ipv4
ipv6-frag ipv6-tcp ipv6-udp ipv6-sctp ipv6-other ipv6
rss active: none
tx burst function: (not available)
rx burst function: (not available)
tx frames ok 5
tx bytes ok 606
rx frames ok 67
rx bytes ok 7910
extended stats:
rx_good_packets 67
tx_good_packets 5
rx_good_bytes 7910
tx_good_bytes 606
rx_bytes 8178
rx_unicast_packets 4
rx_multicast_packets 63
tx_bytes 606
tx_unicast_packets 3
tx_multicast_packets 2
VirtualFunctionEthernet1a/e/3 2 up VirtualFunctionEthernet1a/e/3
Link speed: 10 Gbps
RX Queues:
queue thread mode
0 main (0) polling
TX Queues:
TX Hash: [name: hash-eth-l34 priority: 50 description: Hash ethernet L34 headers]
queue shared thread(s)
0 no 0
Ethernet address e6:86:4e:83:8b:74
Intel iAVF
carrier up full duplex max-frame-size 9022
flags: maybe-multiseg tx-offload intel-phdr-cksum rx-ip4-cksum int-unmaskable
rx: queues 1 (max 256), desc 1024 (min 64 max 4096 align 32)
tx: queues 1 (max 256), desc 1024 (min 64 max 4096 align 32)
pci: device 8086:154c subsystem 1028:0000 address 0000:1a:0e.03 numa 0
max rx packet len: 9728
promiscuous: unicast off all-multicast off
vlan offload: strip off filter off qinq off
rx offload avail: vlan-strip ipv4-cksum udp-cksum tcp-cksum qinq-strip
outer-ipv4-cksum vlan-filter vlan-extend scatter rss-hash
rx offload active: ipv4-cksum scatter
tx offload avail: vlan-insert ipv4-cksum udp-cksum tcp-cksum sctp-cksum
tcp-tso outer-ipv4-cksum qinq-insert vxlan-tnl-tso
gre-tnl-tso ipip-tnl-tso geneve-tnl-tso multi-segs
mbuf-fast-free outer-udp-cksum
tx offload active: ipv4-cksum udp-cksum tcp-cksum multi-segs
rss avail: ipv4-frag ipv4-tcp ipv4-udp ipv4-sctp ipv4-other ipv4
ipv6-frag ipv6-tcp ipv6-udp ipv6-sctp ipv6-other ipv6
rss active: none
tx burst function: (not available)
rx burst function: (not available)
local0 0 down local0
Link speed: unknown
local
The interfaces passed by the host are usually connected to the network (a network switch/router). This means that VPP has direct access to the network as if it were running on bare metal. The container is giving us some isolation so that we use the right interfaces, but it’s not adding any overhead at all.
Plugging Workloads to VPP
If we want to use VPP to connect to VM-based workloads, it supports exposing or connecting to a vhostuser socket that can be hooked to a hypervisor and then exposed as a NIC to a virtual machine. The process of exposing a vhostuser socket to a VM as a network interface is done by the hypervisor itself. Inside the VM, the kernel finds the right device driver (in this instance virtio-user) to communicate with that NIC, just like any Linux kernel would do on any NIC. The result is that VPP sees all packets coming out of that virtio NIC, and it can send packets to the VM through the NIC. From here onward, it's business as usual. Let’s create a vhostuser interface in our VPP instance:
vpp# create vhost-user socket /run/vpp/mysocket.sock server
VirtualEthernet0/0/0
vpp# show int VirtualEthernet0/0/0
Name Idx State MTU (L3/IP4/IP6/MPLS) Counter Count
VirtualEthernet0/0/0 3 down 9000/0/0/0
vpp#
And we also see our socket in the target directory:
$ ls -al /run/vpp/
total 28
drwxr-xr-x. 1 vpp vpp 4096 Sep 29 11:12 .
drwxr-xr-x. 1 root root 4096 Sep 29 09:21 ..
srwxr-xr-x. 1 vpp vpp 0 Sep 29 09:21 api.sock
srwxr-xr-x. 1 vpp vpp 0 Sep 29 09:21 cli.sock
srwxr-xr-x. 1 vpp vpp 0 Sep 29 11:05 mysocket.sock
You can read more about vhostuser usage here.
Conclusion
In this post we talked about what user space networking is, why the Linux network stack doesn’t meet our needs, and how the DPDK libraries can help overcome that. We also demonstrated a living VPP application, gave it a DPDK NIC and created a vhost user socket.
There are other uses for VPP, including IPSec termination, CGNAT, Network Tunnel termination and MPLS and SRv6 forwarding, but covering all that would make this post extremely long and boring. You can learn more in the official documentation.

Ready to kick the tires?
Use code DEPLOYNOW for $300 credit