What to Know When Devising Your Multiregion Backup Strategy
An introduction to backup architectures and configurations, maintaining data consistency, optimizing recovery time objectives and ensuring compliance with data protection regulations.

Last year, Toyota saw its domestic manufacturing plants grind to a halt when its IT backup failed during a routine maintenance procedure. Servers used for parts ordering, both primary and backup, were on the same system, the company explained in a statement, and an error in a primary server that had run out of disk space was replicated on a backup one. It took roughly two days to transfer data to a larger-capacity server, restore the system and bring the plants back to normal operation. Toyota apologized to partners and customers and assured them that the outage had not been caused by a cyberattack.
Incidents with the potential to severely disrupt business operations—whether the cause is mundane or sinister—are inevitable. While there’s little your team can do to prevent human error or being targeted by a ransomware gang, it can devise a backup strategy that will at best keep the business running through the incident and at a minimum give the system a fighting chance at a quick recovery.
In this article we’ll explain the key concepts involved in creating a solid backup strategy, focusing on multiregion backup. Implemented correctly, this approach gives you the most resilience. Backup and recovery are a broad topic area, and here we will cover the basics to give you a starting point for further exploration. We will go over the different backup architectures and configurations, maintaining data consistency, optimizing recovery time objectives and ensuring compliance with data protection regulations.
Is Your Data Safe Where It Is?
Several options exist for backing up your data and ensuring your clients (including people and applications) can access it.
Backup replication can occur at multiple levels, local through global:
- Local replication (on the same machine) protects against disk failure, but not full server outages.
- Replicating to a second system in the same location offers more protection but doesn't cover data center outages.
- Backing up to multiple regions offers the highest level of availability and the most disaster recovery capabilities.
Choosing the right level is important. If technical and financial considerations allow it, you should consider replicating across multiple regions for applications with little tolerance for downtime. That additional location can also be a way to reduce the physical distance between some subset of your users and the data, which, in addition to high availability, can significantly improve the performance of your data access operations.
Moreover, regulations often require regular data backups across multiple locations. If your industry uses something like ISO 27001, a framework for secure information management, you have to include multiregional backups in your data architecture.
How to Select Your Regions
Selecting the right regions depends on what is tolerable latency for your application and where in the world its users are located. If you have users accessing data from different places on the globe, it's ideal to select a set of locations that places a data source as close to each group as possible to reduce latency.
The regulations you must abide by are another big factor to consider. For example, some countries require that the data you manage for a client should never leave the geographical area; in those cases, make sure to select regions that allow you to comply with such regulations.
Regions vs. Zones
If you're using a cloud provider, you need to differentiate between two main levels of location separation: Availability Regions and Availability Zones.
A region refers to a distinct place in the world: a geographic region, such as North America or Western Europe, or a metropolitan area. When it comes to data backups, multiple regions need to be far enough apart that the likelihood of a single disaster impacting both is minimal. For major cloud providers, a region is generally composed of several zones.
A subdivision of a region, an Availability Zone is also a distinct place (often its own data center) but in close proximity to other zones. Zones are intentionally placed close to one another and interconnected, so that performance on the clients’ end is the same, whichever zone in a region they use.
Replication Is Not Backup
Replication and backup are different things, and it’s important to understand the difference.
Data replicated across multiple regions must be synchronized. A synchronization system is implemented to coordinate the data state between locations. Data replication is usually done as quickly as possible to minimize data loss when an issue occurs.
There is an inherent risk when replicating data across multiple locations. If one data source starts writing the wrong data in a critical field (say, a badly encoded string in the name), this quickly propagates to the other data sources. If data corruption occurs and is not immediately noticed, a replicated data source will continue to have the same issue, which is not helpful for recovery.
In contrast, a backup is a snapshot in time of the data source. Backups are designed to create copies of your data and retain them for a certain period. Full system backups are usually not taken too often as the computational cost would be too high. Instead, a full snapshot is taken at an appropriate time frame and during low usage times. The full backup is complemented by incremental snapshots taken with more frequency.
Data Topologies: Full Mesh and Hub-and-Spoke
Two common data replication approaches are data meshes and hub-and-spoke. In a data mesh, all the data locations are interconnected, offering high network availability but introducing potential inconsistencies because of the complexity of coordination across locations. Each system in this setup targets different levels of data consistency based on its specific use case.
The alternative to a data mesh is hub-and-spoke. In a hub-and-spoke model, a central hub manages data replication and ensures consistency across nodes. However, if the hub fails, the system can't sync data. In a situation like this, only data already present in each node can be read, and a limited amount of write operations can be saved while waiting for the hub to come back online. The risk of data loss increases dramatically during this period. This could be mitigated using a high-availability architecture in the hub itself, but it increases complexity and costs.
Data Consistency
When you have information in more than one place, you have to consider how you're going to keep this data consistent. There are two ways of going about this:
- Synchronous replication: With synchronous replication, when data is updated in one source, the same update is sent to the others. This is expensive since you effectively process each request multiple times, but your data is very consistent. This approach can also result in higher latency in confirming the operation with the client, as it needs to wait for confirmation on each write before proceeding.
- Asynchronous replication: With asynchronous replication, changes are made in the original data source immediately, but updates to other locations happen in batches after a set time. This can lead to data inconsistencies if requests come in before replication occurs, but it allows better control over replication costs.
Backup Configurations
At a high level, there are two backup configurations: active-active and active-passive. Both work best when implemented across multiple regions.
Active-Active
In an active-active data architecture, you have at least two sets of data sources that sync with each other constantly, and both of them serve your clients:
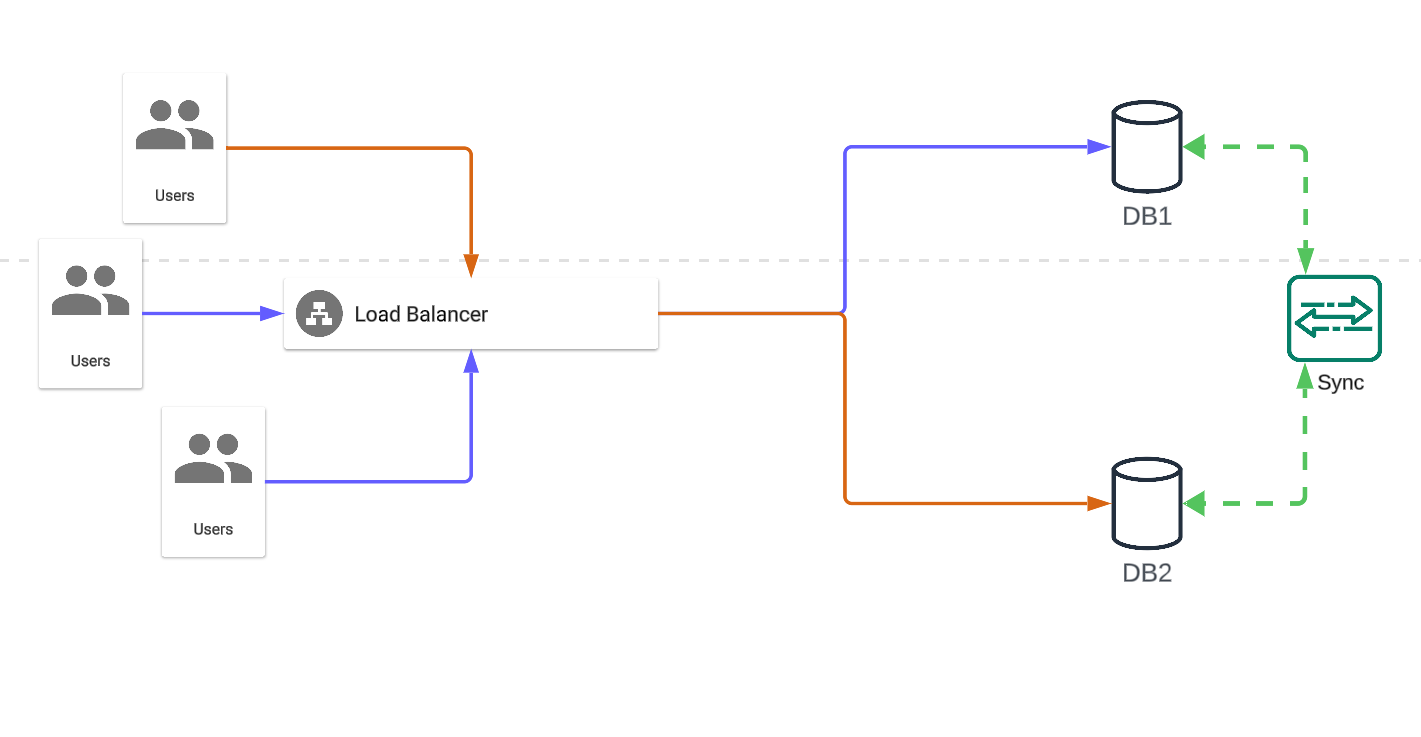
In an active-active configuration, if a disaster affects one of your data sources, you'll immediately fall back to the other source(s). Each one of your data sources is actively serving requests, which means the system as a whole continues to operate. This configuration gives you time to bring a new copy of your infrastructure online without disruption to your clients.
The immediate downside of an active-active, high-availability architecture is cost. You're paying for at least twice the infrastructure you would be paying for otherwise. Your data replication strategy also needs to be fast and bidirectional; this usually carries a higher cost with cloud providers or more technical hurdles if you decide to build the data replication software yourself.
An active-active configuration also tends to be more complex to maintain and monitor. With more compute nodes working at the same time, it's more likely that something could go wrong. This issue can be mitigated by a well-architected autoscaling or failover configuration, but that again adds to the complexity. That being said, active-active is a very well understood architecture, and there are plenty of resources that can help you implement it. (Here's a collection of guides on redundancy and backups by Equinix.)
Active-Passive
In an active-passive data architecture, you deploy your active infrastructure in a single region and serve your clients from there. In this configuration, the data source in the second region constantly replicates the information from the first and sits on standby in case something happens to the first one:
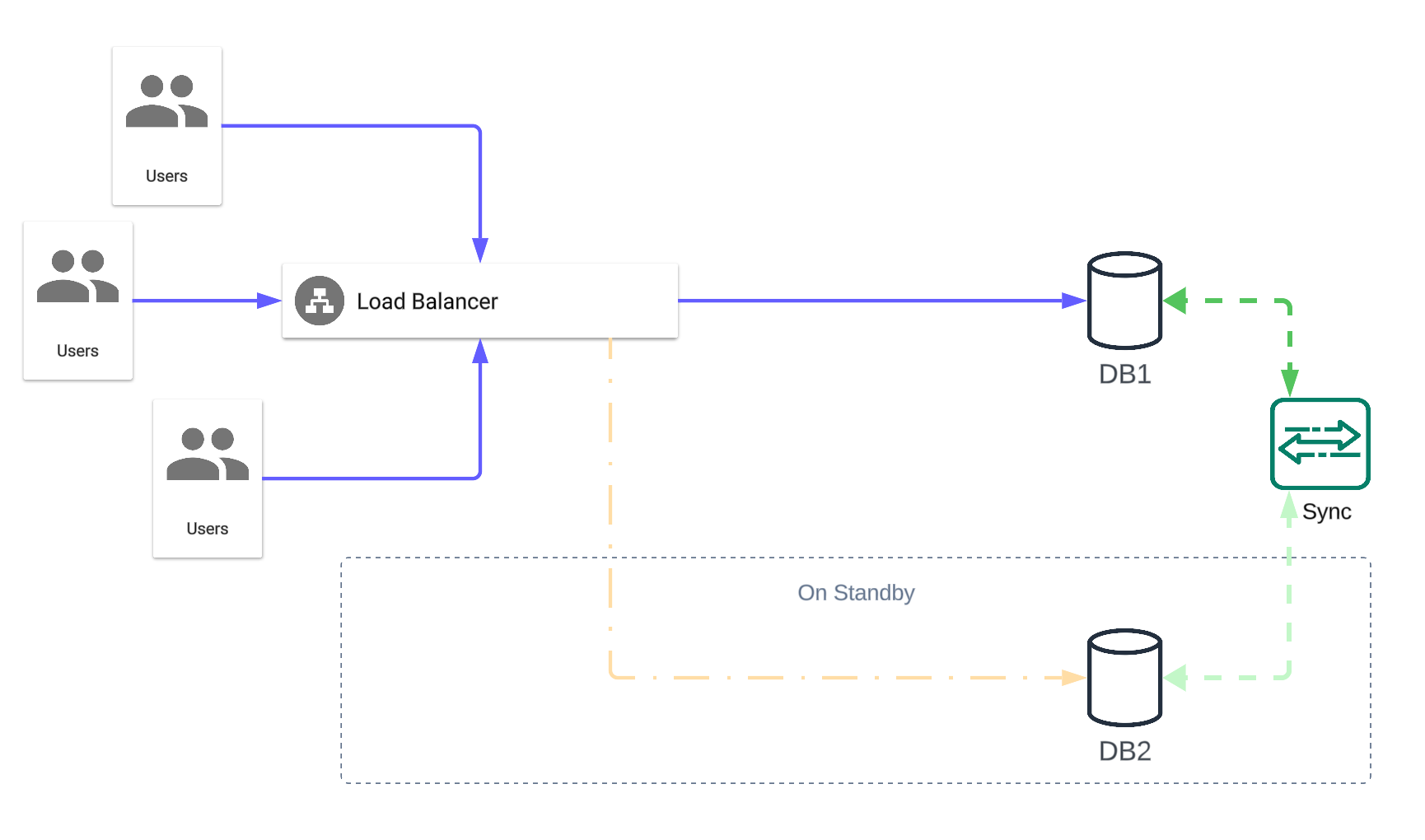
While this configuration is often more cost-effective than active-active due to its unidirectional data replication, recovery time is a key consideration. No matter how good it is, activating a standby infrastructure and redirecting your clients inevitably takes more time than simply redirecting to an already active server.
If you need to ensure that no request is lost and your data is always available to your clients, then you need to spend some extra money and use an active-active configuration. If you have a robust deployment pipeline and don't mind some downtime, you can save money as well as deployment and monitoring complexity by taking the active-passive approach.
Recovery Time Objective and Recovery Point Objective
Recovery Time Objective (RTO) refers to the target you set for your data recovery strategies. It's the maximum acceptable amount of time it can take from the moment there is an incident that prevents access to your data, to when the incident is resolved. In contrast, recovery point objective (RPO) refers to how much data would be lost in the case of failure. Would the last minute be lost or the last hour?
In an active-active configuration, RTO and RPO are almost immediate if the remaining region can handle the increased load, even if data access latency increases. In an active-passive situation, the RTO depends on how you're deploying the standby infrastructure. The RPO is determined by how fast you can rebuild your data sources to the desired state. This is done by taking snapshots with a specific frequency and then saving a record of the changes made to those snapshots. The combination of how long it takes for the new infrastructure to be made available and how long it takes to apply the changes determines your final RTO.
When falling back to a new infrastructure, you need a tool to orchestrate the transition in the event of a disruption. A CI/CD pipeline that implements an infrastructure-as-code tool is your biggest ally. Depending on the technology stack your organization uses, here are some of the best options:
- Terraform is widely accepted in the industry as one of the biggest provider-agnostic tools for infrastructure orchestration. It has a straightforward state management system and module reusability. Until recently, it was completely open source and has a huge community around it.
- OpenTofu is a fork created from Terraform when Terraform stopped being open source. It's gaining popularity fast and keeps all of Terraform's main features.
- AWS CloudFormation is a proprietary declarative language for AWS infrastructure deployment from the biggest cloud provider in the world. If your infrastructure sits entirely on AWS, it's an adequate option to consider; it's easy to learn and plays nicely with AWS's services and features.
Cost Considerations
If cost weren't a consideration, everyone would design an infrastructure that replicates data along several zones in several regions in an active-active configuration, with backups set to recover in seconds after a trigger is activated—but in most situations, this is a bit much. The reality is that for most organizations, the sweet spot falls somewhere between the extremes, and finding this spot is as much an art as a science.
When thinking about data replication and backup strategies, it's easy to focus on the additional storage, but the supporting infrastructure and communication between sites are just as important.
If you're hosting your own data replication strategy, you have several things to consider. If you don't currently have a second location, you have to consider the costs associated with setting up the infrastructure, securing data connections across sites and securing the location. If you already have multiple locations, you need to consider the costs of procuring new hardware, additional power consumption, work time for the people who will set it up and maintain it down the line, and compute requirements to handle replication and monitoring for the new systems.
If you're not hosting the backups or replication strategies, vendors are happy to handle the complexities for you and charge you for it. Every time the data goes into or leaves the cloud, you will incur an egress fee. There are also fees for data transfer between different data centers, regions or zones, and some vendors will also charge you data transfer fees between different services inside those locations. You also have to consider recurring storage costs associated with the size of your backups. Prices can vary by region, so review the cost breakdown for your chosen vendor carefully. And finally, never compromise data security for short-term savings—losing data can be far more costly and damaging.
After reading this article, take a look at your organization and consider what regulations you must comply with. Be sure to cover those first, then go deeper and think, what is your RTO? Do you know it? What would happen if you ran out of space on a critical server? What if it bursts into flames? All of these scenarios are best considered before they happen. Now, contrast the economic impact of those cases occurring against the projected costs of a robust data replication and backup strategy and choose the one that makes your balance sheet happier.
Equinix provides automated single-tenant compute and storage globally (billed as you go) with direct, high-bandwidth, low-latency connections to public clouds. Used as backup infrastructure, it gives you full control of your data, where it’s stored, how it travels over networks and where and how it egresses to the public internet (if at all).