You May Not Require Kubernetes, But You Do Need Kubernetes
We don’t need no Kubernetes; we don’t need no kubectl.
If you don’t have Pink Floyd stuck in your head right now, I’m rather disappointed. However, let's focus on that first statement: “We don’t need Kubernetes” is something I hear all too often, and I would like to take this opportunity to expand the thinking on the “need” for Kubernetes.
While I often hear “We don’t need Kubernetes,” I’m not often in a position to dig into that justification, especially over the last year as events are virtual and conversations happen on the macro level. I decided to be as scientific as possible and get some opinions from the world’s smartest technologists…so I tweeted.
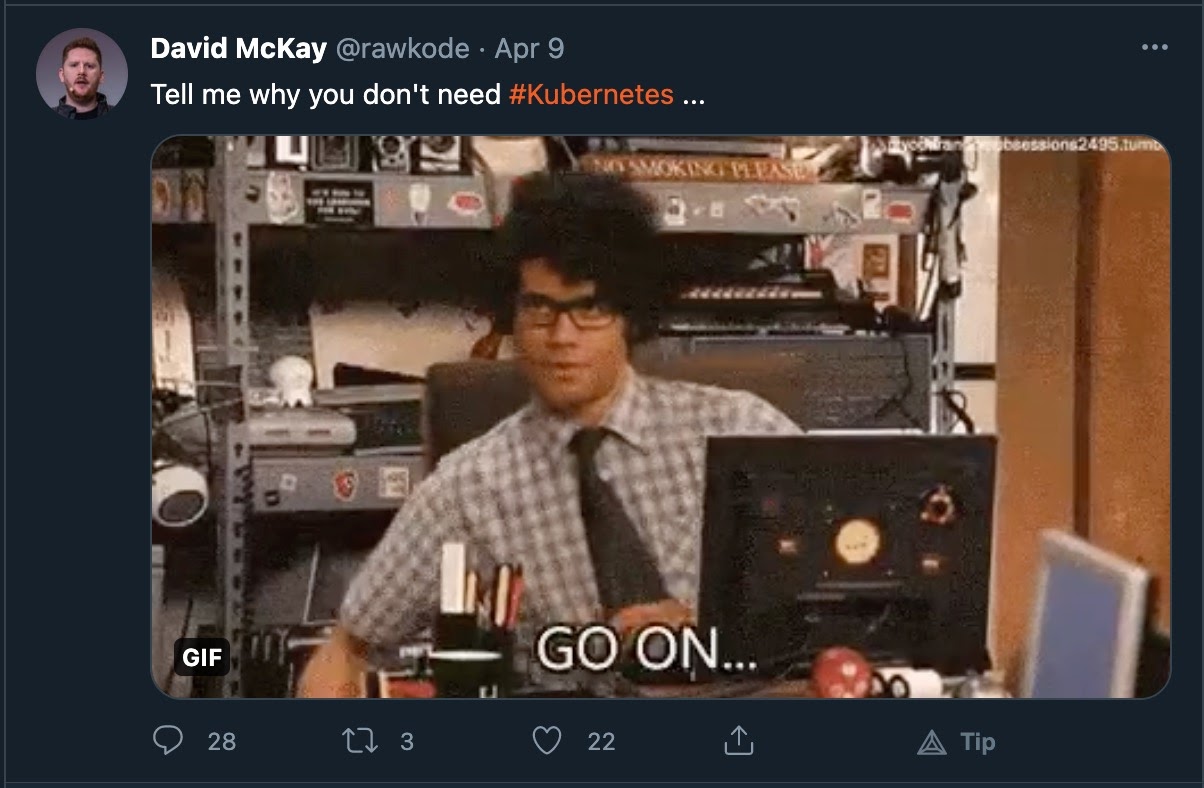
The responses varied widely from genuine concerns to sarcastic retorts. I’ll highlight just a few.
Firstly, two responses from some friends; Tim Banks and Dan “POP” Papandrea.
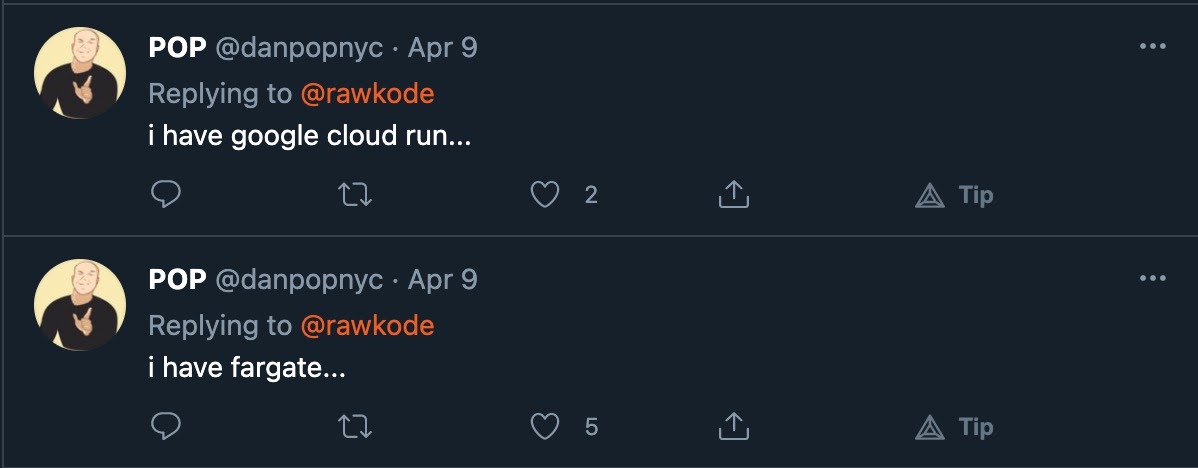
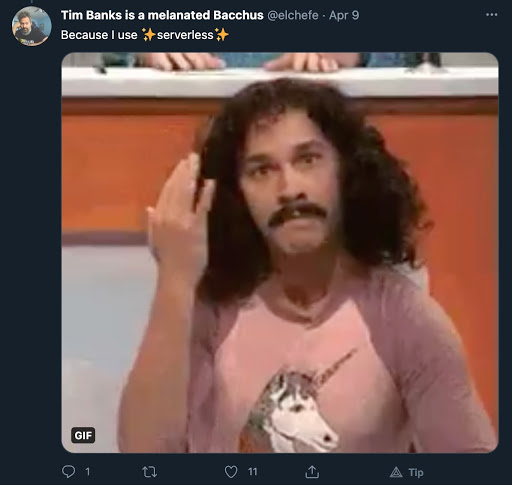
While I presume they were being rather facetious, Dan and Tim are suggesting that serverless (especially managed serverless products from public cloud providers) is an alternative to Kubernetes. They are correct. However, Kubernetes adoption is accelerating with such velocity because organizations and teams want to abstract away vendor lock-in and work with agnostic APIs that are owned and supported in a neutral way, for example, by the CNCF. That doesn’t mean that orgs and teams won’t use cloud providers and the many services they provide; of course they will, but they’re often preparing and allowing themselves the flexibility to change providers as required. So while you can definitely build and be successful with serverless, and vendor lock-in, that’s a decision each org needs to make cautiously. It’s also worth noting that Cloud Run is based on Knative, an open source Functions as a Service (FaaS) framework for Kubernetes. So we don’t sacrifice running “serverless” workloads when adopting Kubernetes, we just sacrifice the serverless misnomer.
OK, let’s tackle a few more responses.
A timely joke from Paul Stack, “mesos is better…”, related to the recent almost-attic’d Meso.

Niche PHP joke from William: “Why run apache when you can implement your own fast cgi adapter for your app?”:

A “so scary it’s true” reply from Rich, “Because I already have a bunch of static VMs that I track in this Excel spreadsheet *bursts into tears*”:

Followed by Jason’s response. Yes, Cluster API Jira Provider is a thing :joy:
Amusing as they all are (and I laughed a lot), let's take a look at the “real” answers.


From these answers, we can see a recurring theme. There’s a lot of worry and concern about the complexity of Kubernetes, the scale required to justify Kubernetes, and the operational support needed to keep its lights on.
These are all extremely valid concerns, but I feel there’s another side to this story that needs to be told.
Adopting Kubernetes
“One small step for man, one giant leap for mankind” ~ Neil Armstrong
Why the hell am I quoting Neil Armstrong, the first man to walk on the moon? Great question, reader. Did you know that the average composition of the moon's surface, by weight, is roughly 43% oxygen, 20% silicon, 19% magnesium, and 10% iron? Did you know the temperature of the moon varies from 273F/134C to -243F/-153C?
I’ve never been to the moon (NASA, I’m ready), but I know about the moon's surface composition and variable temperatures because people much brighter than me have been there, have walked on the moon. We even have people that continue to study our moon, and the broader solar system, using satellites, rovers, and even remote control helicopters from 292.82 million km away. While I’m seriously doubting my sanity as I compare the scientific genius of Kubernetes to something as silly as lights flickering in space to send commands and telemetry to a piece of metal on another planet, I want us to understand that we’re now at a stage of operating, understanding and adopting Kubernetes that you can take a small step to make a giant leap.
With every major cloud provider offering a managed Kubernetes service, you don’t need to build, run, and manage your own clusters. AKS, DOKS, EKS, and GKE is the best way for all to start taking advantage of Kubernetes. Let these Kubernetes monoliths handle the difficult parts so that you can stand on their shoulders.
I actually mean that literally. Adopting Kubernetes used to be a competitive advantage for the early adopters, but by NOT adopting Kubernetes, it’s now a competitive disadvantage. Kubernetes has crossed the chasm, its ubiquity is clear. Kubernetes, core, has over 3000 contributors with over 100k commits. There are over 125k members on the Kubernetes Slack. Gartner even predicts that 70% of organizations will be running three or more containerized applications in production within two years.
Kubernetes brings us so much convention in the way we build and architect our cloud native systems that I feel that adopting Kubernetes, for all workloads regardless of size or complexity, still has a net positive for your organization. While learning Kubernetes may be hard, you’re tapping into a collective knowledge. Kubernetes won’t be the last thing you learn, but it’s the bedrock of everything you’ll learn over the next 10 years; even if you don’t touch Kubernetes directly - its primitives are now the foundation for whatever tooling you are.
Lastly, before we dive deeper into the collective knowledge, I would love to highlight K3s. K3s, by our friends at Rancher Labs at SUSE, is a “Lightweight Kubernetes” for IoT and edge computing. You don’t need to be working with hundreds, or even dozens, of containers to take advantage of the Kubernetes convention; you can do this now with a single binary on even the smallest device.
If you’re still reading, it’s probably because your interest is piqued by “collective knowledge” and my proclamation that the Kubernetes convention can make you as smart as a rocket scientist. So let's take a look at some of this convention and get familiar with how you, your team, and your org can tap into this collective knowledge.
Kubernetes
When we bring Kubernetes into our organizations, we can lay to rest a whole raft of distributed compute (pun intended) problems that traditionally we’d need to solve ourselves. By deploying our workloads to Kubernetes, we get containerized deployments that have DNS-based service discovery through `kube-dns` baked in. Kube-dns is an in-cluster DNS service that speaks Kubernetes. It means we can ask for “mariadb” and magic happens.
Since Kubernetes is a collection of controllers that run in a continuous loop, waiting for events and opportunities to reconcile, we can add probes to our manifests for our workloads and have those controllers know when our pods are unhealthy, and then they can be restarted. Kubernetes also ships with a scheduler, hooks for Container Networking Interface (CNI) and Container Storage Interface (CSI) implementations, and Cloud Controller Managers (CCMs). These allow scaling horizontally and vertically across any number of nodes, provisioning and attaching block devices, network configuration, monitoring, and security, and integrations to your cloud provider of choice.
NOW is the right time to start evaluating Kubernetes. The challenges that existed three years ago, sometimes six months ago, are mostly solved. You’re now in the luxury position of joining the slipstream and enjoying the fruits of the difficult migrations that others have labored before you.
This is the “out the box” functionality of Kubernetes; some assembly required, two people may be required for some heavy lifting. Even those moments are rare now, thanks to kubeadm and managed stacks.
But wait, there’s more ...
Artifact Hub
The Artifact Hub is a CNCF project to provide a central repository for lots of different projects within the cloud native space. You can find Tinkerbell actions, Kubectl plugins, and Tekton tasks. As cool and awesome as those are, I want to highlight three others: Helm Charts, OPA Policies, and Falco Rules. These three allow anyone to deploy 3rd party software to Kubernetes while ensuring best practices for policy and security. Deploying software we don’t write ourselves is usually the biggest hurdle and challenge, nevermind doing that in a safe and secure fashion.
Helm Charts
I don’t think Helm needs much introduction anymore; it’s become the de facto way to deploy third-party applications to Kubernetes. Members of the cloud native community from around the world help maintain these charts that allow us to deploy mongoDB, PostgreSQL, MariaDB, and much much more. They include best practices from operators that have managed these applications before, often including maintainers from the projects themselves. I used databases because we all find them super difficult to manage, more so on Kubernetes. At the time of writing, there are 2799 charts available on the Artifact Hub. Nearly 3000 pieces of software that you don’t need to learn how to deploy on Kubernetes.
OPA Policies
The Open Policy Agent (OPA), a CNCF project, is a general-purpose policy engine that unifies policy enforcement across the stack. OPA provides a high-level declarative language that lets you specify policy as code and simple APIs to offload policy decision-making from your software. You can use OPA to enforce policies in microservices, Kubernetes, CI/CD pipelines, API gateways, and more.
Sadly, there’s only one OPA policy on Artifact Hub … however, it’s a pretty good one! Deprek8ion, by Steve Wade, using OPA to monitor your Kubernetes cluster for usage of deprecated APIs. Kubernetes is a fast-moving project, although it is getting slower, so you need to keep on top of it’s API, where deprecations are all too familiar (I miss you v1beta1).
Now, just because there’s only 1 OPA policy on Artifact Hub doesn’t mean there’s not more collective knowledge for us to tap into. I believe more policies will come to the Hub in time, but for now, we can also look to OPA itself, and its Gatekeeper project. Speaking of deprecations, Kubernetes recently deprecated PodSecurityPolicies (PSP). A feature that many of us used to restrict the capabilities of pods within our clusters. Gatekeeper, and Kyverno, have been tasked with replacing this functionality in user-land. You can find all the OPA policies to replace PSPs here. Beyond PSPs, Gatekeeper has policies in its library for best practices too, such as labeling pods, requiring probes, and blocking node port services. These are all day 2 concerns that are extremely easy to miss but vitally important.
I do hope we see more contributions to Artifact Hub with more collective knowledge with regards to policy; I think it’s just a matter of time.
Falco Rules
Falco is another CNCF project that focuses on runtime security, configured with Falco Rules, available on the Artifact Hub. Falco hooks into the Linux Kernel (eBPF) and to Kubernetes (Audit) and allows you to monitor and react to suspicious events.
Falco can check for privilege escalation, read/write syscalls to well-known directories, unexpected network connections, process spawning, and so much more. Falco is awesome. Known what you can, should, could do with Falco is not so awesome … unless we go to the Hub.
Right now, Artifact Hub has 23 different Falco rules for you to leverage. That number is small, but it’s growing and packs a rather large punch. These available rules include Fluentd security to keep your log pipeline in check, security rules for mongoDB, Consul, Elasticsearch, etcd, nginx, PHP FPM, PostgreSQL, Redis …. you get the point. You don’t need to understand what “normal” looks like for this software to get alerts when they begin to act untoward.
Operator Hub
Another tool for the collective good aims, like Helm, to solve the problems associated with operating third-party software. Unlike Helm, which only deploys the software, Operators have become a new pattern for reactive operations against said third=party software. It’s all well and good to deploy PostgreSQL to your cluster, but what happens after that? Can we leverage the knowledge and experience of PostgreSQL operators within our own cluster?
The OperatorHub is separate from Artifact Hub, but provides a similar experience. You can use the Hub to find and get installation instructions for operators that cater to a wild array of applications. These operators are under constant evolution, bringing more and more operational experience to even the smallest of clusters, often supported by the maintainers of the software they operate. Operators help us tackle more of these day 2 concerns, helping the software we run in our clusters stay healthy and happy even during a little turbulence. With Operators for Kafka, Elasticsearch, Cassandra, PostgreSQL, and Prometheus; you don’t need to be an expert in distributed databases and their operations.
Kubernetes is hard, yes. Kubernetes is complex, definitely. Your existing infrastructure was likely those things too, only now you’ve got automation and knowledge that is less transferable to new teams and organizations, nor can you leverage the Kubernetes collective knowledge for your own. Take solace in knowing that dozens, if not hundreds, of thousands of people have already walked the path, sharing their stories at KubeCon, HackerNews, Twitter, Dev.to, Slacks, blogs, and everywhere else.
Happy Kuberneting!

Ready to kick the tires?
Use code DEPLOYNOW for $300 credit