How to Architect a Data Platform
The 13 layers of a modern data platform, what they do and when your organization needs them.

If you work at a large multinational organization, you're likely surrounded by tools that process immense amounts of data daily. Every transaction, order, website visit, contact, or sensor measurement is recorded in some kind of data storage system.
Connecting the right data points, using adequate technologies to analyze the data, creating algorithms and developing data applications can all create a competitive edge in marketing, sales and operational efficiency. The data platform that enables this edge by putting data to work consists of several different data layers that constitute the data lifecycle, starting with the production and ingestion of data and ending with consumption for analytical purposes.
In this article, you'll learn about the data layers a modern data stack architecture requires, and why each of them is important.
More on data platforms:
What Layers Could a Modern Data Platform Have?
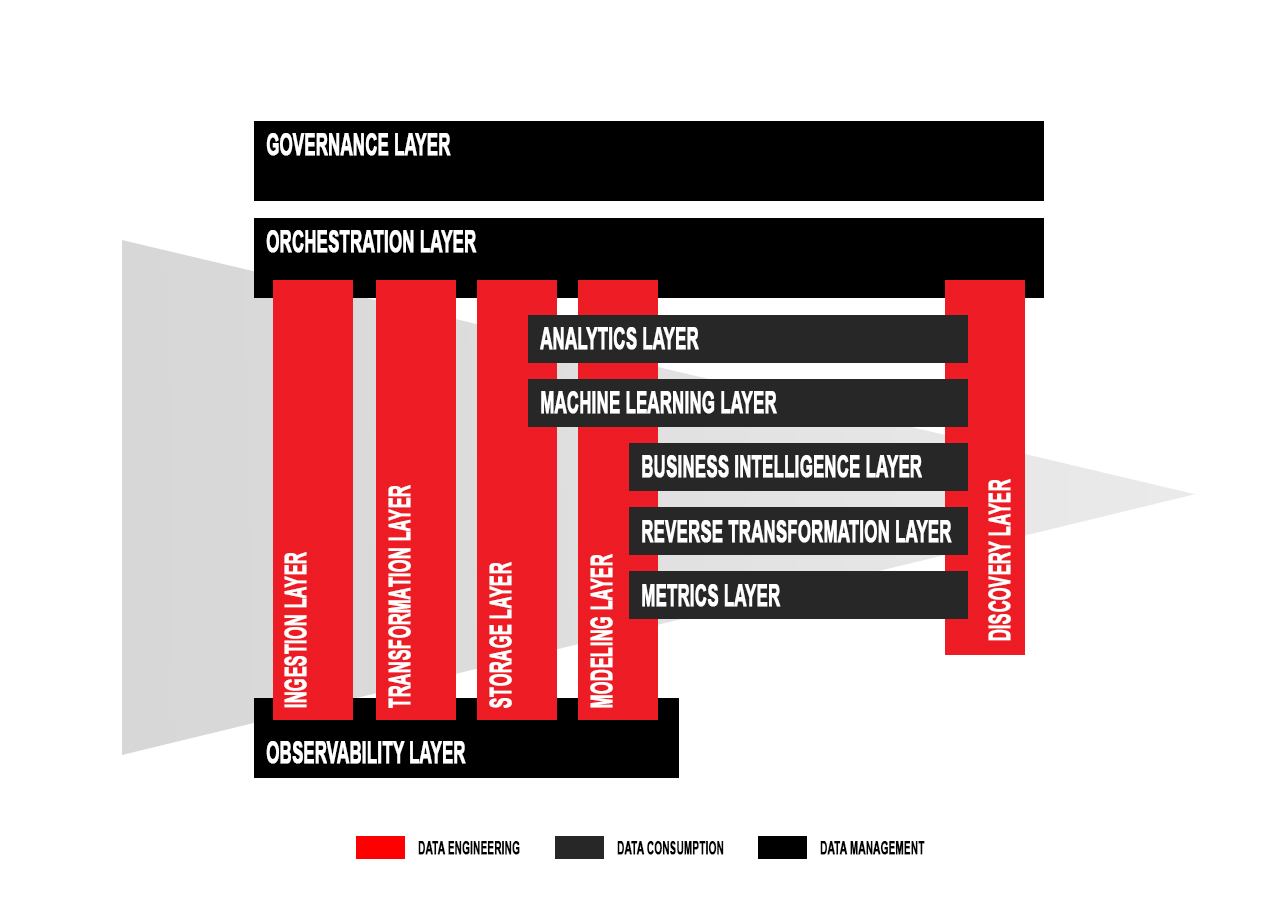
While there are a few end-to-end data platforms on the market, many organizations choose to work with a highly modular tool stack consisting of various best-of-breed tools that can be expanded to cover future use cases. Additionally, over the years many tools have successfully occupied adjacent layers, competing with tools they once worked in tandem with. We will highlight some of the prominent instances.
Ingestion Layer
An ingestion layer is indispensable to organizations with highly varied data sources.
Data comes in numerous formats: batch jobs via APIs; CSV, JSON and XML dumps on a server; production databases; and data streams. The ingestion layer is where connections to this hodgepodge of sources takes place. It's also the first line of defense against anomalous data—the first opportunity to detect it.
While some organizations have built their own ingestion layer, connecting to numerous APIs, webhooks and databases is an arduous task, prone to breaking down. This is why several vendors have taken on the task of maintaining these connectors. Fivetran was one of the first to enter the market and used to be a data-community favorite. But many competitors have emerged since, including Airbyte, Stitch and Matillion.
Data Transformation Layer
A transformation layer, often substitutable for or incorporated into the modeling layer (which we’ll cover shortly), is essential to all organizations.
While the transformation layer is often conflated with the data modeling layer, there are significant differences. Data transformation truly manipulates data or stores a manipulated copy of it.
Data transformation typically happens in one of two (or both) phases in the data lifecycle. It can happen "in flight," before the data is stored, omitting the original data entirely. Or, it can happen after the data is stored, preserving the original version. Transforming data has two main purposes: improving data quality and reducing the data footprint by only storing a subset of the ingested data.
Fairly popular data transformation tools are Apache Beam and its Google Cloud Platform proprietary version Google Dataflow. These days, however, few standalone data transformation tools are out there, as many organizations have adopted data platform layers that rely on Apache Spark, which can be used for data transformation workloads among other things. Additionally, the cost of data storage has gone down, so the need for transforming data before storing it isn’t as urgent.
The spectacular rise of the data modeling layer has spurred a paradigm shift: from extract, transform, load (ETL) to extract, load, transform (ELT). Instead of transformations being applied sequentially, many are only executed on the fly, when an end user accesses them through a query. Think database views on steroids.
Data Storage Layer
You can’t not have a storage layer, can you?
While a lot of data is stored in online transaction processing (OLTP) databases (like Postgres, SQL Server or MySQL), analytical jobs require specific storage capabilities, often referred to as online analytical processing (OLAP). The "A" in the acronym refers to an "analytical" usage pattern, which is typified by three operations that are executed during descriptive data analysis: aggregation, drilling down and filtering. An OLAP storage system should store data in such a way that processing these ad hoc queries is a matter of seconds, minutes and occasionally hours.
Storage layers come in three flavors: data warehouses, data lakes and data lakehouses (a hybrid version of the former two). A pure data warehouse typically excels at storing and processing structured data at blazing speed, often with atomicity, consistency, isolation and durability (ACID) guarantees and support for database metadata and constraints. Data lakes, on the other hand, are file-based and thus support semistructured and unstructured data with a processing technology of choice.
The rise of file formats such as Delta Lake, Hudi and Iceberg kicked off the convergence of data warehouses and lakes towards the lakehouse. Lakehouse-based systems have a strict separation between file-based data storage and processing engines, such as Spark, Dremio and Presto. Many data warehouse vendors, such as Snowflake, Redshift and BigQuery, have also launched support for one or more data-lakehouse file formats.
Data Modeling Layer
A modeling layer, which, again, is often substitutable for a transformation layer, but also for a metrics layer, is indispensable to all organizations.
Modeling data is the process of creating a representation of an information system that reflects how all tables relate to one another before serving it to data consumers.
Data modeling has existed as long as database technology. In the 1990s and early 2000s, flocks of data engineers were hired to process and model transactional data into data cubes for analytical purposes. However, the abysmal performance of data cubes and the tedious process of loading new data shattered the illusion of an organization's data-driven panopticon.
Nevertheless, tools like dbt have made data modeling popular again. By extending SQL with templating capabilities, SQL statements reflecting business logic can be reused. Unlike transforming data, modeling doesn't necessarily require storing the manipulated data, as data models are often executed lazily.
A popular data modeling tool besides dbt is Dataform (acquired by Google in 2020 and integrated into GCP).
Data Orchestration Layer
An orchestration layer is important for organizations with fragile data pipelines, typified by varying processing times.
To prevent data pipelines from breaking, the steps for ingesting, transforming, storing and modeling data should happen more or less sequentially. Transformations shouldn't be executed before their upstream dependencies have been ingested. When there are only a few data pipelines and they're not very complex, a sequential execution of data pipelines could be achieved through simple cron jobs. However, when there are multiple technologies involved and data products have multiple upstream dependencies, a data orchestration layer is a functional requirement for managing this choreography of technologies.
Popular orchestration tools are Airflow (or its SaaS version, Astronomer), Dagster and Prefect.
Data Observability Layer
An observability layer is crucial for organizations whose data pipelines are essential for business operations and for whom downtime carries a huge cost.
As data pipelines become increasingly complex, they become harder to update and debug. Data observability reflects an organization's ability to understand the overall state of its data platform. High observability is imperative for maintaining, debugging and fixing data pipelines with minimal downtime.
Data tools within a data platform produce logs and metrics that you can use to understand data quality and reliability. The data observability layer processes this stream of evidence and provides end-to-end lineage of an organization's data. Typically, data observability tools come with specific types of intelligence in the form of ML-driven anomaly detection models that automatically detect the root cause of an issue.
Popular best-of-breed data observability tools are Monte Carlo and Telmai.
Analytics Layer
An analytics layer is indispensable to organizations that want to perform complex ad hoc analyses on large amounts of data.
The layers discussed thus far are responsible for preparing data for consumption. Data is ready to be consumed once it has been ingested, transformed, stored and modeled. There are various ways to turn data into value. One is providing answers to ad hoc questions. These questions are often fairly complex and cannot be answered through a simple visualization. Going beyond descriptive analytics—into the realm of predictive and prescriptive analytics—requires statistical inference.
These kinds of analyses are increasingly performed in data science notebooks. Popular notebook tools are Jupyter (self-hosted), Google Colab and Amazon SageMaker. There are also best-of-breed SaaS vendors, such as Hex and Deepnote.
BI Layer
A business intelligence (BI) layer is a must-have for organizations whose business users rely on data-driven insights.
The BI layer is also used to consume data, but unlike the analytics layer, it focuses on offering standardized reports for recurring decision making: daily planning, monthly sales and quarterly financials.
In most organizations, the BI layer is the only layer that employees in business departments interface with. For many of them, BI reports are crucial for fulfilling their tasks. That's why these kinds of reports and visualizations need to be frequently and automatically updated.
There's a wide array of BI tools to choose from. A few of the popular ones include Tableau, Microsoft Power BI and Looker. There are also some alternatives worth considering, including GoodData, Mode and Sisense.
Reverse Transformation Layer
A reverse transformation layer is important for organizations that need to synchronize their data manipulations and augmentations with many third-party SaaS tools.*
Another consumption layer, the reverse transformation layer, or "reverse ETL," is the opposite of the ingestion layer. Instead of bringing data from various sources into the data platform, the reverse transformation layer synchronizes the data back to components such as ERPs, CRMs and communication tools. Because most of these tools require incoming data to conform to certain standards, this layer makes a final transformation.
While popular tools such as Census and Hightouch used to follow a true best-of-breed approach, they are both now moving into adjacent markets.
Machine Learning Layer
A machine learning (ML) layer is indispensable to organizations that are looking to develop and deploy models in their automation efforts.
The ML layer is responsible for training, deploying, serving and monitoring algorithms. While data scientists use the analytics layer for crafting highly specialized models, their work is often passed on to the ML layer. Machine learning comes in several flavors: structured data vs. images/video/audio/text, hyperparametrization vs. AutoML, feature engineering vs. feature augmentation (generative AI), transfer learning vs. starting from scratch, etc.
Because the field of artificial intelligence is moving so incredibly fast, it's hard to pinpoint which software categories and tools will prevail. GCP Vertex AI, Amazon SageMaker, and Azure ML Studio are excellent general ML tools. But there are also some powerful niche tools, such as Snorkel, Evidently, Roboflow and Neptune.
Metrics Layer
A metrics layer is a must-have to organizations where operators work from within a single application.
A metrics layer (or semantic layer) is an extra abstraction on top of the data modeling layer. Instead of offering users data products such as schemas and tables, a metrics layer presents highly standardized metrics inside business users’ tools. This guarantees that the users are all looking at the same, uniformly defined metrics, independent of where they consume them.
The market for metric stores is quite niche. A best-of-breed tool is Cube, but with its acquisition of Transform, dbt now has this functionality built in.
Data Discovery Layer
A discovery layer is indispensable to organizations with many data assets and many data consumers.
The data discovery layer is a solution to a fairly recent problem. Large organizations have been spending tremendous amounts of money and manpower to get data out of production systems and into their data platforms. Many have used it to build numerous data products. The problem they often run into now is that nobody knows what all the data means, where it comes from, or which data products it's used in.
The data discovery layer offers a solution. At its core, it's a data catalog, but there’s more to it. Modern data discovery tools can suggest relevant data objects when one would least expect them through recommendations and advanced search features.
Popular data discovery tools are Atlan and Collibra.
Data Governance Layer
Organizations with complex data assets or high regulatory responsibilities cannot go without a data governance layer.
Data governance reflects the degree to which an organization has control over its data. In environments with high regulatory pressure (data privacy laws, for example) or complex data assets, a data governance tool is no luxury. Data governance encompasses many aspects of the data lifecycle: data quality, data access, documentation and often discovery.
Some tools that tackle one or more data governance aspects are Talend, Immuta and CastorDoc.
Conclusion
We covered several layers of a typical data platform. Few organizations require every layer. Thankfully, modern data platforms are often highly composable; tools can be added to the data stack as the business requirements shift or the environment changes.
A successful data platform must be flexible and scalable enough to support your development operations without compromising on security or compliance. If you are building a robust, scalable data stack, Equinix dedicated cloud offers the ideal infrastructure building blocks on demand and as a service, including storage, compute, networking and private connectivity to all the major cloud platforms and SaaS providers, so that you can leverage the best tools available while retaining full control of your data.

Ready to kick the tires?
Use code DEPLOYNOW for $300 credit