How We Fixed Our Users’ Networks When Submarine Cables Broke
A straight-forward backbone BGP configuration change would reroute customers’ traffic. And it did, but not without things getting weird first.

The internet is an amazing feat of infrastructure engineering. We enjoy global connectivity because there are hundreds of cables running from continent to continent along the ocean floor. You can probably appreciate that operating roughly 1.4 million kilometers of cable laying thousands of meters deep is hard. You can probably also imagine that sometimes the cables fail. A distracted fishing boat captain might drag an anchor in the wrong spot on the seabed and cut a cable. An underwater earthquake may cause an outage.
Repairing a broken submarine cable is hard, expensive and takes weeks—or months. It requires dispatching a specialized ship to sail out on the ocean, find the break, haul the cable up and fix it. But submarine cable networks are resilient. There are plenty of alternative paths for internet traffic to take when a single cable goes down. An outage of this kind is a non-event, as far as users are concerned. However, outages on multiple cables on a route happening all at the same time are an event users do notice (albeit a rare one). It congests the cables on the route that aren’t down, degrading connectivity for everyone who is using them.
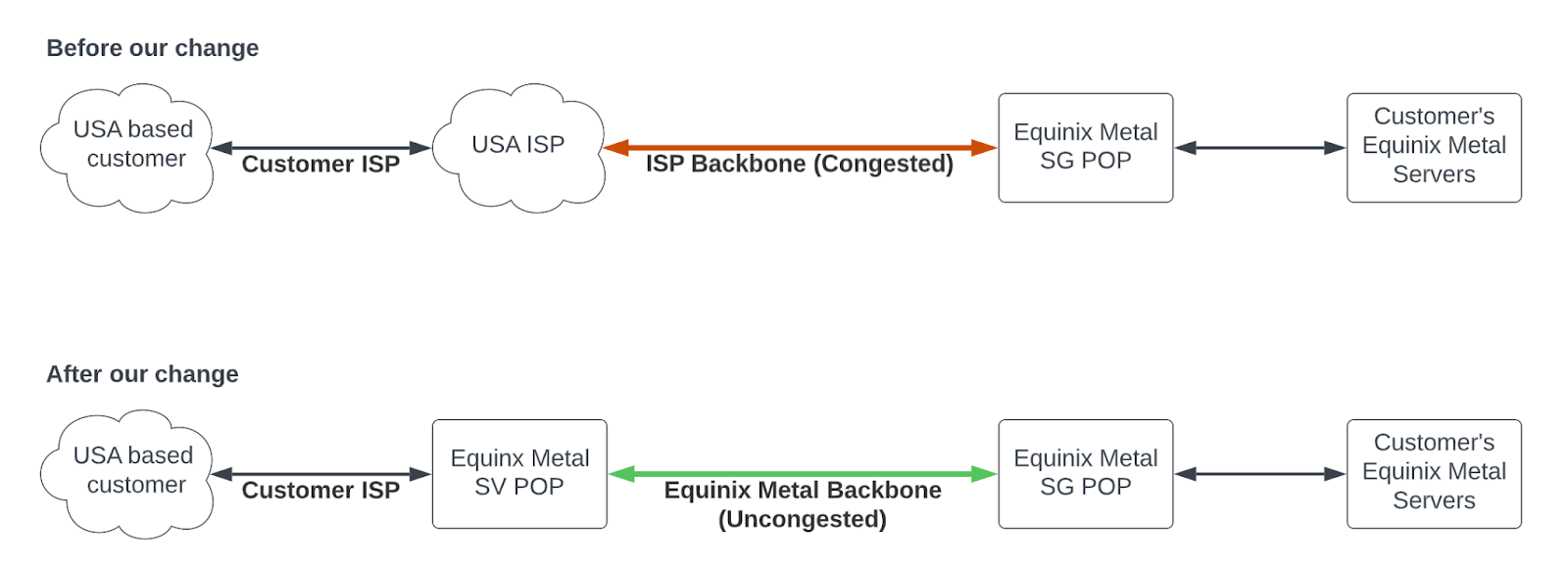
Earlier this year, Equinix Metal customers sending traffic between North America and Asia Pacific over the internet were facing exactly this issue. Multiple cable outages were causing congestion on the ISP backbones on the route, and our customers who were using those ISPs saw their performance slump. Because we operate our own, private network backbone that wasn’t affected, we saw an opportunity to help them out by tweaking the BGP configuration on our network.
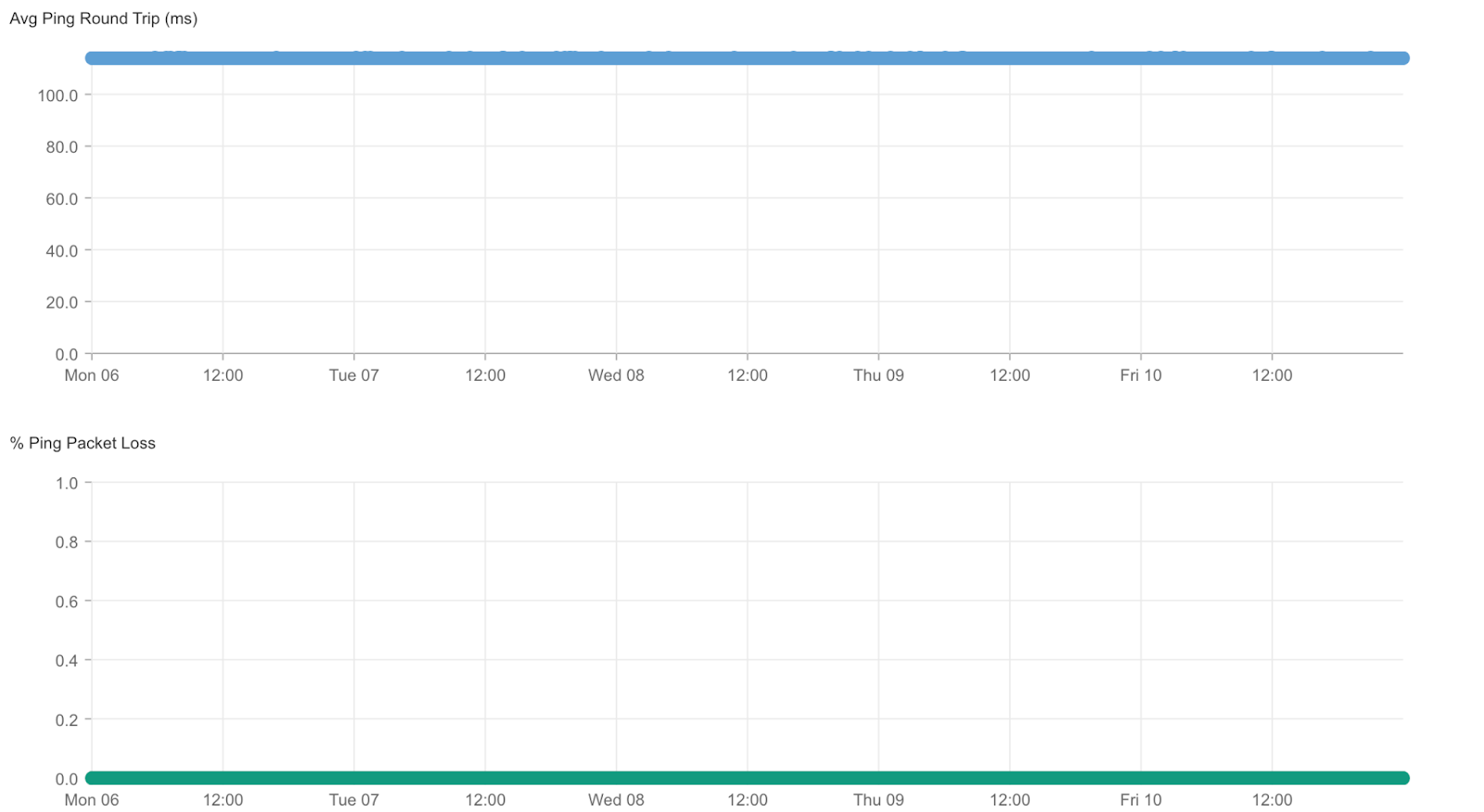
Our backbone connects all the data centers around the world where we provide our bare metal cloud services. We call these locations “metros.” If a customer has servers in multiple metros that communicate with each other, that traffic travels over the Metal backbone, never leaving our network. Because it’s private and dedicated to Metal, our backbone was not congested as a result of the submarine cable outage. There was no packet loss, and latency levels were normal between our metros in Asia Pacific and North America:
Our plan was to change our BGP configuration so that we could carry our customers’ internet-bound traffic between North America and Asia Pacific on this private backbone instead of leaving them to suffer through the congestion on their ISPs’ networks. For example, instead of traversing numerous ISP networks to get from somewhere in the US to our Singapore POP, a customer’s traffic would come into our POP in Silicon Valley and hop onto the Metal backbone to get to the Singapore Metal POP. It would work the same in reverse.
Basics of the BGP Configuration On Our Backbone
To make the story about the execution of our plan easier to tell, let me explain a few things about the way the Equinix Metal backbone works.
The control of routing information between Metal metros is handled by BGP, or Border Gateway Protocol, which ensures that the network has all the information it needs to get traffic where it needs to go. There are two types of BGP, internal and external. Internal BGP (IBGP) runs between all the routers on our backbone. We use external BGP (EBGP) to talk to our ISPs and peers.
One of the rules for IBGP peers meant to ensure everything works correctly is that a peer cannot advertise routes it learned from one peer to another peer. This rule exists mainly to prevent creation of routing loops. It means that all IBGP peers in a network must be peered in a full mesh in order for all routing information to be advertised correctly. This is hard to manage at scale, because it can lead to hundreds or thousands of BGP sessions per device. The formula for calculating the number of peers for a full mesh is N(N-1)/2. So, having 10 routers, for example, will result in 10(10-1)/2 = 45 sessions. A hundred routers will result in 100(100-1)/2 = 4,950 sessions. You can see how poorly this scales.
A workaround is using route reflection to reduce the amount of IBGP peering sessions required. Route reflectors allow IBGP routes received from IBGP peers to be advertised to other IBGP peers. This means IBGP routers only need to peer with the route reflectors—not all other IBGP peers. The Metal network runs four global route reflectors, or RRs, and all our backbone routers have IBGP sessions to them.
Here’s a high-level diagram of the topology using Singapore as an example:
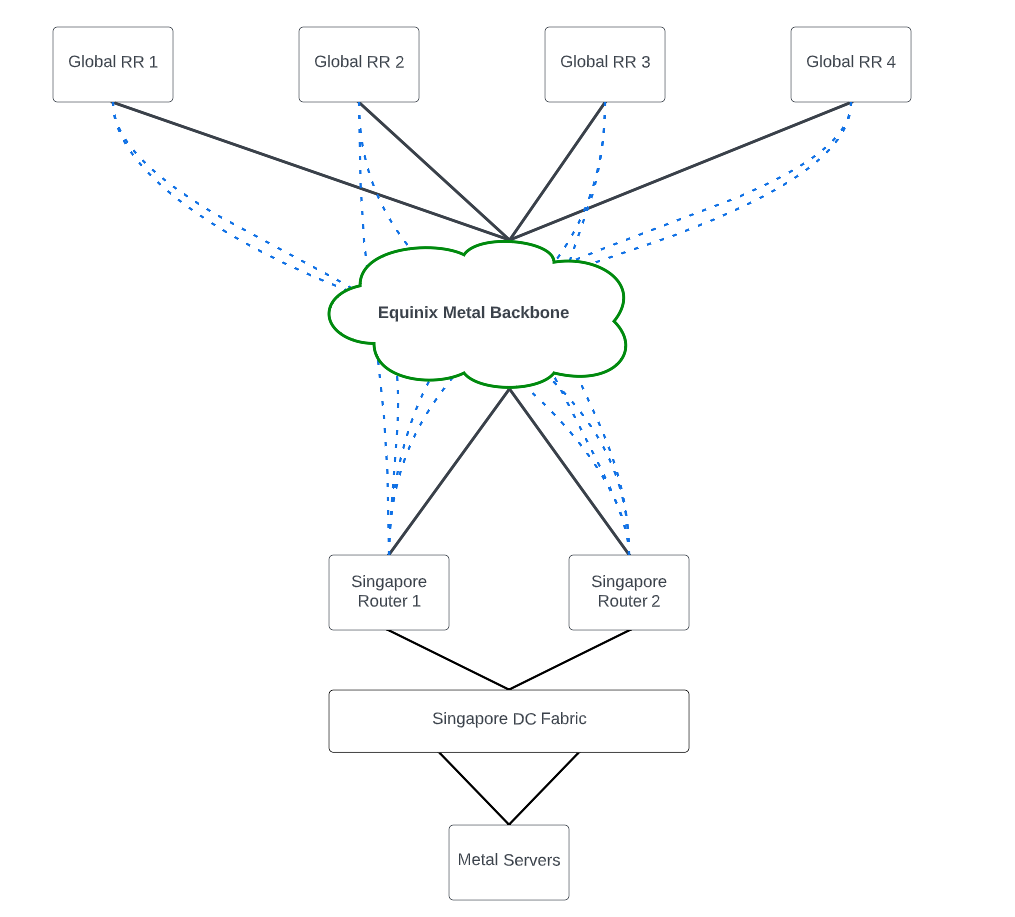
As shown, our border routers in Singapore are connected to the Metal backbone, as are the global RRs. The dotted blue lines indicate the IBGP sessions each router has to each global RR. Global RRs are placed in various Metal metros (SG, SV, NY, AM), and each metro’s border routers maintain IBGP sessions with them.
Applying the BGP Configuration Change
We made our first attempt to implement the BGP configuration change that would enable our customers’ internet traffic to circumnavigate their ISPs’ congested backbones on March 15. The steps, at a high level, were:
- Advertise APAC subnets to our ISPs in SV
- Advertise internet routes originating from North America to our RRs
- Update the RRs to allow the internet routes originating from North America to be sent to our APAC routers only
On Step 3, however, things started to go wrong. We noticed a surprisingly high amount of traffic coming into our SV metro and going out to our providers. We had expected traffic to increase, but not by this much! Taking a closer look, we saw that the traffic was coming from Metal sites all over the world, not just APAC! We also started to get packet-loss alerts from various sites, and a few customer complaints. We rolled back the change and started investigating.
Chasing Down the Culprit
Troubleshooting led us to a route reflector, which, instead of advertising internet routes originating from North America only to APAC, was advertising them to all our regions. This was confusing, because our RRs have strict export policies designed to prevent this exact problem. We organize our BGP sessions on the RRs in groups based on region, and the BGP configuration for the APAC group looks like this:
luca@rr1.sv5> show configuration protocols bgp group APAC-RR-CLIENTS | display inheritance no-comments
type internal;
local-address <removed>;
mtu-discovery;
log-updown;
import APAC-RR-CLIENTS-IN;
family inet {
unicast {
add-path {
receive;
send {
path-count 2;
}
}
}
}
family evpn {
signaling;
}
export APAC-RR-CLIENTS-OUT;
The important line in the above config is the last one: export APAC-RR-CLIENTS-OUT. This policy determines exactly what gets advertised to BGP peers who are members of this group. This was the policy we adjusted to make the change by adding a new term: SV-NORTH-AMERICA-TRANSIT.
luca@rr1.sv5> show configuration policy-options policy-statement APAC-RR-CLIENTS-OUT | display inheritance no-comments
term PACKET-INTERNAL-VRF {
from community PACKET-INTERNAL-RT;
then accept;
}
term PACKET-BLACKHOLE {
from community PACKET-BLACKHOLE;
then accept;
}
term SV-NORTH-AMERICA-TRANSIT {
from {
protocol bgp;
community [ AS3257-NORTH-AMERICA AS1299-NORTH-AMERICA ];
}
then accept;
}
term PACKET-ORIGINATED {
from {
protocol bgp;
community [ PACKET-ALL-ORIGINATED PACKET-ALL-CUSTOMER PACKET-ALL-GLOBAL-IP PACKET-ALL-ANYCAST PACKET-ALL-DEPROV_AGGS ];
}
then accept;
}
then reject;
This term matches all prefixes from two ISPs (Telia and GTT) that contain a specific origin BGP community that each ISP uses to tag routes originating from North America. We saw these prefixes being correctly advertised to APAC routers, but they were also—incorrectly—going to other metros. We did not make changes to any other export policies to other regions:
luca@rr1.sv5> show configuration policy-options policy-statement US-EAST-RR-CLIENTS-OUT | display inheritance no-comments
term PACKET-INTERNAL-VRF {
from community PACKET-INTERNAL-RT;
then accept;
}
term PACKET-BLACKHOLE {
from community PACKET-BLACKHOLE;
then accept;
}
term PACKET-ORIGINATED {
from {
protocol bgp;
community [ PACKET-ALL-ORIGINATED PACKET-ALL-CUSTOMER PACKET-ALL-GLOBAL-IP PACKET-ALL-ANYCAST PACKET-ALL-DEPROV_AGGS ];
}
then accept;
}
then reject;
So, what was happening? After running some tests, we saw the problem on the RR in SV:
luca@rr1.sv5> test policy US-EAST-RR-CLIENTS-OUT 1.7.210.0/24
inet.0: 3248 destinations, 11775 routes (3248 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, * = Both
1.7.210.0/24 *[BGP/170] 00:11:48, MED 100, localpref 600, from 136.144.54.64
AS path: 1299 9583 I, validation-state: unverified
> to 198.16.4.114 via xe-0/1/0.0
[BGP/170] 00:11:47, MED 100, localpref 600, from 147.75.204.20
AS path: 1299 9583 I, validation-state: unverified
> to 198.16.4.114 via xe-0/1/0.0
[BGP/170] 00:11:47, MED 100, localpref 600, from 145.40.70.37
AS path: 1299 9583 I, validation-state: unverified
> to 198.16.4.114 via xe-0/1/0.0
[BGP/170] 00:11:48, MED 100, localpref 600, from 136.144.50.50
AS path: 1299 9583 I, validation-state: unverified
> to 198.16.4.114 via xe-0/1/0.0
*[BGP/170] 00:11:48, MED 100, localpref 600, from 136.144.54.64
AS path: 1299 9583 I, validation-state: unverified
> to 198.16.4.114 via xe-0/1/0.0
Policy US-EAST-RR-CLIENTS-OUT: 1 prefix accepted, 0 prefix rejected
The test policy command above checks to see if the referenced policy will accept or reject a prefix. As shown above, when testing a random internet prefix against the US-EAST-RR-CLIENTS-OUT policy we can see it being accepted where it should be rejected. Checking one of our other RRs, we see the expected result:
luca@rr1.ny5> test policy US-EAST-RR-CLIENTS-OUT 1.7.210.0/24
Policy US-EAST-RR-CLIENTS-OUT: 0 prefix accepted, 1 prefix rejected
luca@rr1.ny5>
The Fix
This unexpected behavior was disastrous, causing North America-bound traffic from all Metal metros to route via our backbone to a single POP in Silicon Valley. Digging deeper, we found that the RR in SV was running a different software version than the other four. We also found some match problem reports (PRs) on the vendor’s website mentioning similar behavior. All signs were pointing to a serious software bug.
After a software upgrade on the misbehaving RR, the same tests showed the policy working as expected. On March 21 we attempted the BGP configuration change again and this time saw no issues. Our customers noticed some nice stability improvements!
While this is an interesting “few-days-in-the-life-of-a-network-engineer” story—we had an issue, tried to fix it, made it worse and then finally fixed it after finding an annoying software bug—it’s worth noting a lesson learned. We have a lab environment that closely resembles our production environment. When tested in the lab, the initial change passed without issues. Donning those perfect “hindsight” glasses, it was because the lab RRs were running the standard software version without the catastrophic bug—obviously! Our big mistake was to assume that all our production RRs were on our standard version, when only three out of the four were. Like most large network operators, we have processes in place to upgrade router code when required, and we’re working on improving the reporting aspect of this process to be more aware of the devices in our network running non-standard code.

Ready to kick the tires?
Use code DEPLOYNOW for $300 credit