BGP Confederations vs. Route Reflectors and How to Choose the Right One
Each method has its use cases in large networks, but the crucial factor is whether your AS is large or very large.

Many organizations rely on Border Gateway Protocol (BGP) to manage routing in large-scale internal networks, such as corporate intranets and data center fabrics. BGP is typically associated with routing between different autonomous systems (ASes) on the internet, but it's also widely used internally to route traffic between segments of an organization's network. When implementing internal BGP (iBGP), meaning BGP neighbor connections between routers in the same AS, two options are available to improve network scalability and manageability:
- BGP route reflectors are centralized BGP speakers that simplify the network topology and reduce the number of iBGP neighbor connections.
- BGP confederations segment a BGP AS into sub-ASes to simplify management while presenting as the original AS to external networks.
If you're a network engineer, DevOps engineer or IT infrastructure manager, this article will help you understand the differences between BGP route reflectors and BGP confederations, including the benefits and drawbacks of each approach. By the end of the article, you'll be able to select the best option for your network based on its technical requirements.
Understanding BGP Route Reflectors and BGP Confederations
A route reflector (RR), as defined by RFC 4456, is a BGP router that simplifies the iBGP routing topology by neighboring with all routers in an AS and advertising learned routes to its neighbors (known as clients), removing the need for a full mesh iBGP routing topology. Alternatively, a BGP confederation, as defined by RFC 5065, enables the subdivision of an iBGP topology into smaller, more manageable networks with their own sub-ASes, which share an overarching AS for connectivity to external networks.
More on BGP:
Traditionally, iBGP requires a full mesh network topology of neighbor connections between BGP routers. This means that for each BGP router (n) in the network, n(n-1)/2 neighbor connections are required. For example, if your BGP network contains twenty routers without the use of BGP RRs or confederations, 190 BGP neighbor connections must be established. This iBGP prerequisite presents major issues in large and growing networks with scalability, manageability and configuration complexity.
For instance, internet service providers (ISPs) need their networks to be scalable to facilitate new capacity during growth periods while ensuring their routing is efficient and resilient. Large enterprises seek to reduce the amount of configuration changes, administrative overhead and downtime when managing their networks. Organizations undergoing rapid growth need to ensure their network easily scales with them, while organizations planning to merge seek to minimize the impact on their business when integrating with other networks. For all these use cases, understanding BGP RRs and confederations, as well as when to implement them, equips you to deploy, manage and expand your BGP network with less complexity, effort and disruption.
Which Approach Is Better: BGP RR or BGP Confederation?
Now that you know there are solutions to the problems caused by iBGP in large networks, let's look at which method is best based on what is required for your BGP network.
Simplicity in Terms of Management and Ease of Use
A BGP RR is easy to configure and manage because it simply requires a BGP neighbor connection from each client router to the router designated as an RR. In an existing AS, implementing a BGP RR is simple; there are no changes to the existing AS number (ASN), while the network topology transitions from full mesh to hub-and-spoke.
Large networks with uptime service-level agreements (SLAs) require resiliency, which means multiple RRs can be configured to avoid a single point of failure. In the case of dual RRs, only two iBGP neighbor connections to the RRs are configured per client router, no matter how large the network grows. To change routing attributes or influence next-hop preferences, it's only necessary to update the neighbor connection to the RRs, and these updates are forwarded across the entire AS by the RRs.
Configuring BGP on Equinix dedicated cloud:
- Configuring BGP with FRR on an Equinix Metal Server
- Configuring BGP with BIRD 1.6 on an Equinix Metal Server
- Elastic IPs with BGP
When using BGP RRs in iBGP-enabled networks, a potential drawback is their simplicity, which can be detrimental in networks needing quick failover in the event of an outage. Since only a single path for each prefix is forwarded from the RR to each client router, BGP fast reroute is unavailable.
When a BGP path fails, the client routers are reliant upon the RR to send an updated path, which takes as long as the RR needs to recognize the failure, select a new best path and send prefix updates. As a result, convergence time is greater than that of a traditional iBGP setup or BGP confederation with redundant paths.
As a BGP confederation segregates a larger AS into smaller sub-ASes, management is similar to that of a traditional AS. The difference is that fewer total BGP neighbor connections are required in the overarching ASN. However, BGP confederations can be complex to use and may lead to routing loops if incorrectly designed or configured. The trade-off is that there is greater control over routing behavior as multiple paths can be shared between neighbors.
In summary, a BGP RR is far simpler than a BGP confederation to configure and manage, especially for smaller networks. However, if your large AS requires optimized routing, advanced traffic engineering and fast convergence, the added complexity of a BGP confederation may be better.
Scalability
BGP RRs and BGP confederations are both employed in large networks for the principal benefit of improved scalability compared to traditional iBGP. As illustrated below, a BGP RR changes the network topology to a hub-and-spoke one, while a BGP confederation creates a collection of interconnected mesh networks:
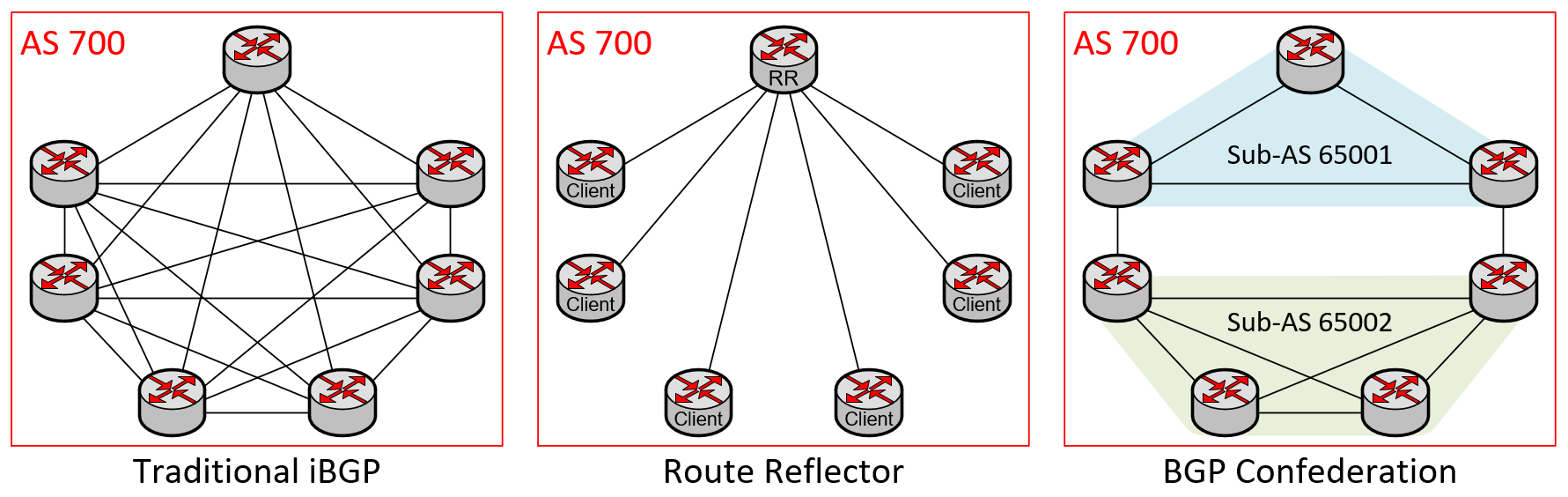
Of the options above, a BGP RR provides ideal scalability for most networks due to its hub-and-spoke topology. For a growing network, adding a new spoke router to the network by connecting it to the BGP RR greatly reduces complexity and administrative overhead. However, as the BGP RR approach relies on a central router to learn and forward all prefix updates within the AS, the scalability of this option is limited by the capacity of the router that serves as the RR, since it contains all the prefixes and paths of the entire AS.
In massive networks (in the order of thousands of routers), the number of prefixes could exhaust the RR's capacity, leading to faults. However, if your network is expected to grow within the limits of your router's hardware and requires reduced management overhead, a BGP RR will meet your scalability needs.
BGP confederations provide scalability by segmenting the BGP network into multiple sub-ASNs. This provides the benefit of increased capacity per sub-AS as the network expands, no matter how large it gets. However, this comes at the cost of added complexity because there is a full mesh of neighbor connections within each sub-AS. The BGP confederation can be broken into a hierarchical topology, simplifying sub-AS management and allowing route summarization across sub-ASes. This reduces the number of prefixes contained in any sub-AS.
Adopting a BGP confederation for scalability only begins to provide value when you're supporting a large network containing hundreds or thousands of routers and you can afford to subdivide your existing AS and manage the collection of sub-ASes.
A design that can provide the best of both worlds is to implement a BGP confederation that hosts BGP RRs within each sub-ASN. This provides the segmentation benefits of BGP confederations and the simplified scaling of BGP RRs.
Performance
In most networks, choosing a BGP RR or confederation makes little difference when it comes to performance throughout the internal network. This is because both options utilize the same underlying iBGP routing functionality. However, there are some considerations if the network has high-performance requirements.
A BGP RR can introduce additional latency compared to a traditional AS topology in two ways. As BGP updates need to transit through the RR, this creates an extra hop for route propagation. The impact on routing updates is typically minimal and is usually acceptable for most use cases.
BGP RRs can also increase latency by introducing suboptimal routing in large networks with multiple routing paths. This is because the RR shares its own best path for each prefix with client routers, which is not always the best path for each router. This can lead to scenarios where latency between networks is higher than if traditional iBGP or a BGP confederation were used.
In addition, this limitation of a BGP RR sharing a single path for each prefix can affect routing convergence. If the RR's best path for a prefix fails, all client routers are reliant on the RR to recognize the failure, compute a new best path and share the update with its clients. This can introduce significant delays in networks with high-availability requirements and uptime SLAs. There are workarounds to this limitation, including BGP additional paths for Internet Protocol (IP) networks and unique route distinguishers per edge router for Multiprotocol Label Switching (MPLS) networks.
A BGP confederation can provide lower latency than a BGP RR because it both reduces the number of hops for routing updates and enables each BGP-enabled router to calculate its own best path for each prefix. This enables optimal routing as well as fast rerouting for prefixes with multiple paths, which reduces the impact of network faults.
However, implementing a BGP confederation can introduce additional bandwidth and processing overheads compared to a BGP RR. Bandwidth overhead increases when each router in the confederation propagates routes between neighbors within and across sub-ASes, which could reduce the bandwidth available for regular data packets. This is especially relevant when there are many large sub-ASes. Moreover, processing overheads may increase in BGP confederations on routers that bridge sub-ASes and must therefore modify the `AS_PATH` attributes in each routing update.
A BGP RR reduces the number of iBGP connections and therefore reduces bandwidth overhead, and the centralization of processing at the RR reduces processing overhead on client routers. However, the performance benefits of reduced overhead may not be as noticeable with today's powerful routing hardware.
Flexibility
As mentioned in the “Simplicity” section, BGP RRs are easier to use than BGP confederations. This leads to superior design flexibility and change flexibility, particularly in growing networks subject to rapid developments in business requirements.
Implementing a BGP RR design is a matter of designating a router as the RR, connecting it to all routers in the AS and removing all other preexisting iBGP neighbor connections. A BGP RR facilitates a centralized network policy that allows you to tweak routing as required to improve the overall design. The hub-and-spoke nature of a BGP RR lends itself to easy addition or removal of routing policy with minimal effort from a configuration perspective compared to a BGP confederation.
If you plan to implement a BGP confederation in an existing AS, keep in mind that you'll need to renumber and reconfigure your entire network. Implementing a BGP confederation requires careful design to avoid potential loops and to maximize efficiency in the number and size of sub-ASes. Changes to routing policy within a sub-AS typically affect only that sub-AS, which minimizes the potential impact of misconfigurations. If modifications are required for the overarching AS, large-scale configuration changes are typically required to align all routers in the confederation.
BGP confederations can be useful in merger scenarios where two BGP networks are required to integrate. A confederation would enable each party to retain its existing ASN and to reduce changes to the existing design while sharing a common overarching ASN with the other party.
Conclusion
In this article, you learned about the iBGP options available that enable organizations to scale a growing network while minimizing configuration complexity. A BGP route reflector and BGP confederation each offer their own advantages and disadvantages in terms of simplicity, scalability, performance and flexibility of each iBGP feature. The following are the key differences between BGP route reflectors and BGP confederations:
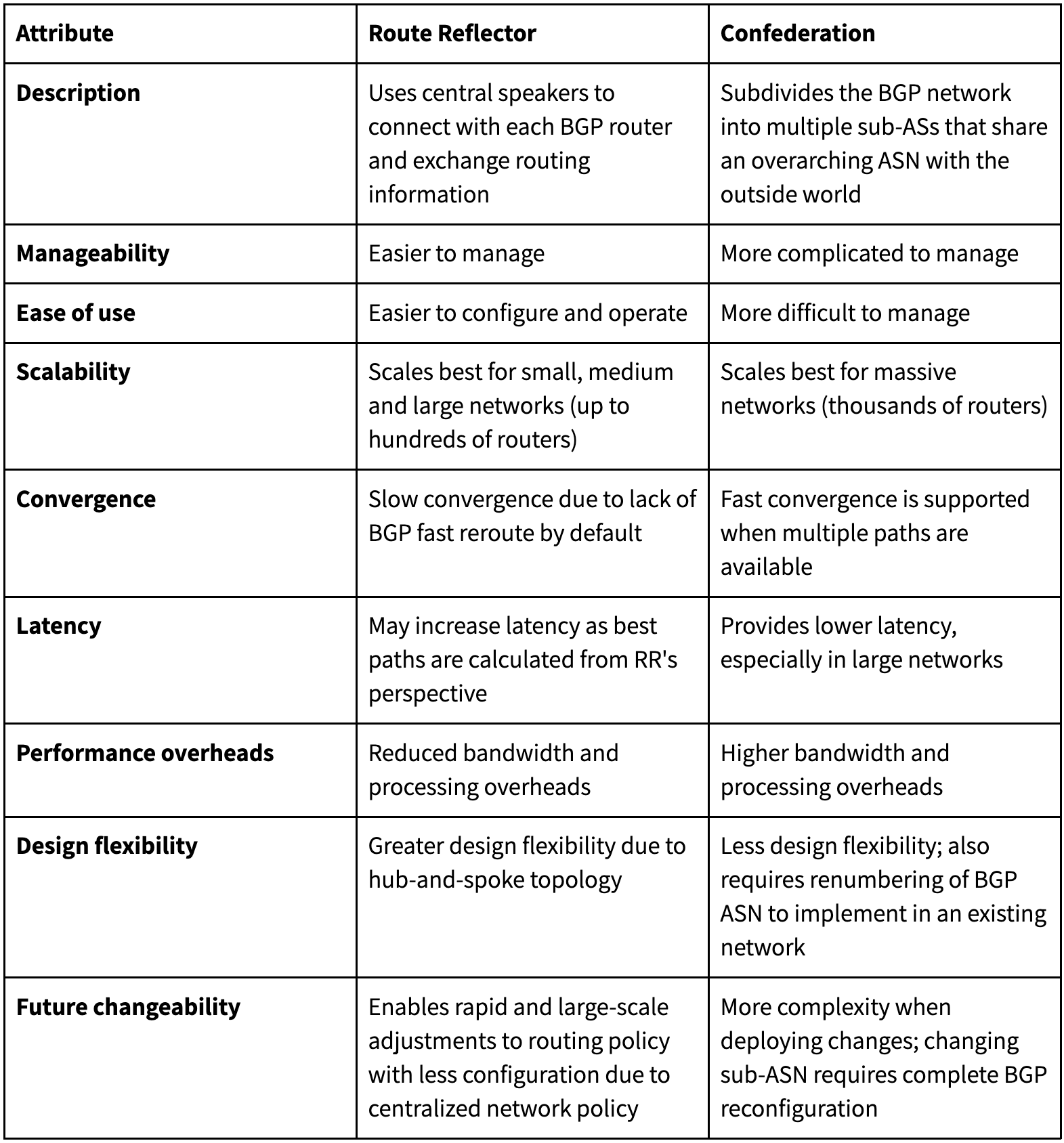
With all this in mind, consider the following points before selecting which iBGP option to implement in your network:
- Do requirements like simplicity of configuration, rapid scalability or future flexibility apply? If so, look at implementing a BGP route reflector as a lightweight solution.
- Do requirements like segmenting a massive AS, merging with another organization's BGP network or maximizing network performance apply? Then designing a BGP confederation could meet your needs as a large organization with extensive resources.
If your organization requires full control of BGP routing on its network, Equinix dedicated cloud networking offers a lot of flexibility in configuring BGP globally, both for private bare metal compute and storage and for connectivity to network providers, enterprises and public cloud providers.